pytorch
【PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】】
https://www.bilibili.com/video/BV1hE411t7RN/?share_source=copy_web&vd_source=f21aab4ae7e1148acd5e06c0dddddfd9
1.环境管理 建立不同的python版本环境(anaconda prompt)
1 conda create -n pytorch python=3.6 #创建一个名为pytorch的环境
激活/进入特定环境
环境下的工具包
安装pytorch工具包
在pytorch官网按照环境复制命令在特定环境进行下载
安装完之后检查pytorch安装情况
1 2 3 python import torch torch.cuda.is_available()
两个工具:pycharm和jupyter
pycharm创建项目记得勾选对应的interpreter(如:D:\Users\lzh\anaconda3\envs\pytorch)
jupyter选择环境:在prompt下命令行开启jupyter:
1 2 conda install nb_conda jupyter notebook
jupyter shift+enter执行并编辑下一行
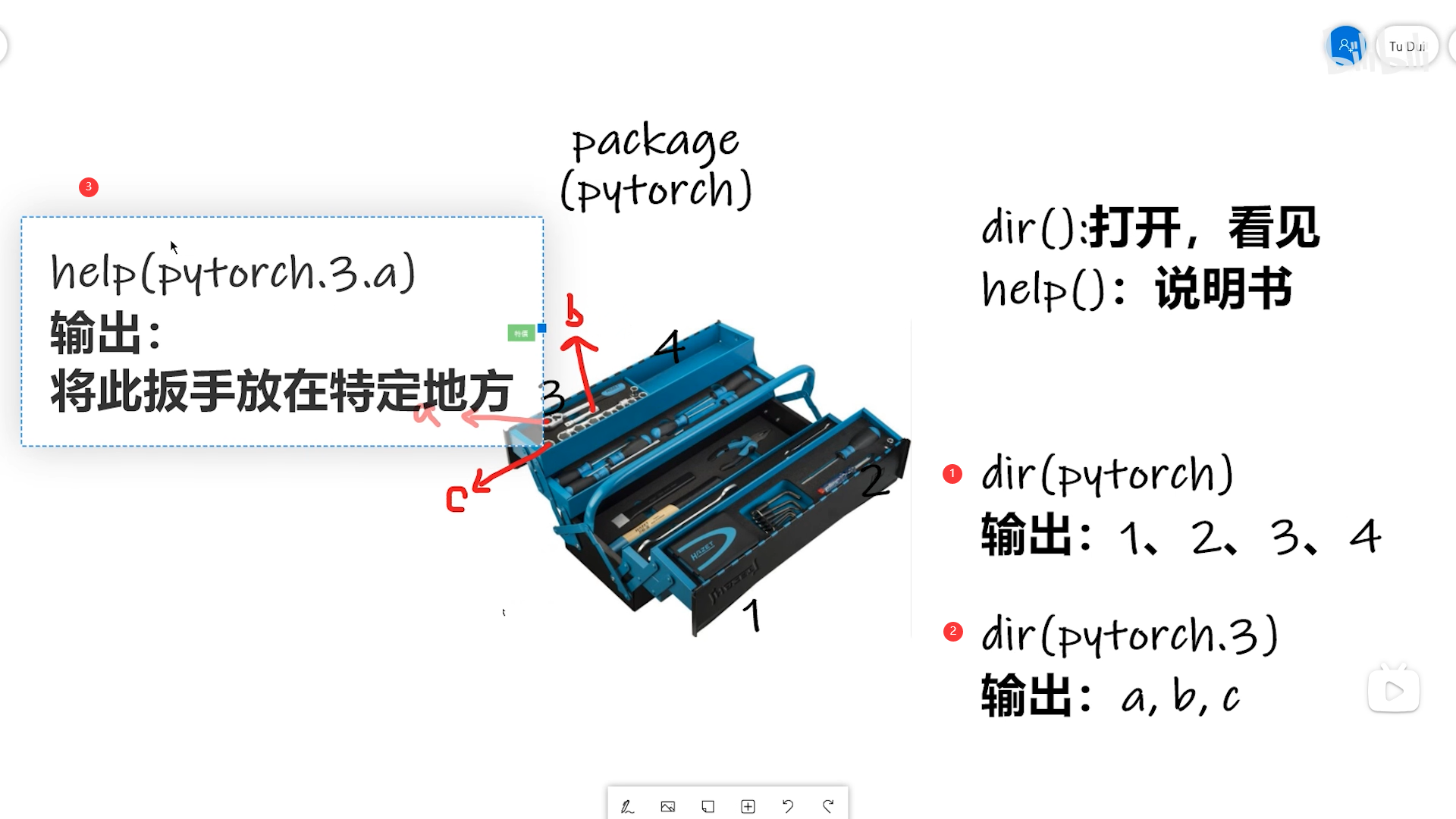
2.两个函数
1 2 3 4 dir(torch) #dir(package) dir(torch.cuda) dir(torch.cuda.is_available) #输出是双下划线,双下划线表示不可修改,此时不能进一步打开了,就是函数了 help(torch.cuda.is_available)
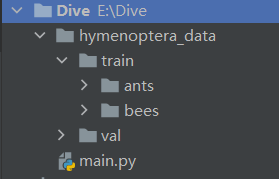
3.数据的加载 两个类:
如果文件夹名称就是label:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 from torch.utils.data import Datasetfrom PIL import Imageimport osclass MyData (Dataset ): def __init__ (self,root_dir,label_dir ): self.root_dir = root_dir self.label_dir = label_dir self.path = os.path.join(self.root_dir,self.label_dir) self.img_path = os.listdir(self.path) def __getitem__ (self, idx ): img_name = self.img_path[idx] img_item_path = os.path.join(self.root_dir,self.label_dir,img_name) img = Image.open (img_item_path) label = self.label_dir return img, label def __len__ (self ): return len (self.img_path) root_dir = "hymenoptera_data/train" ants_label_dir = "ants" bees_label_dir = "bees" ants_dataset = MyData(root_dir, ants_label_dir) bees_dataset = MyData(root_dir, bees_label_dir) train_dataset = ants_dataset + bees_dataset
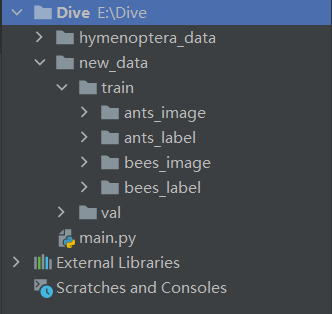
如果分开了img和label:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from torch.utils.data import Datasetimport osfrom PIL import Imageclass MyData (Dataset ): def __init__ (self,root_dir,image_dir,label_dir ): self.root_dir = root_dir self.image_dir = image_dir self.label_dir = label_dir self.img_path = os.path.join(self.root_dir, self.image_dir) self.label_path = os.path.join(self.root_dir, self.label_dir) self.img_name = os.listdir(self.img_path) self.label_name = os.listdir(self.label_path) def __getitem__ (self, idx ): img_path = os.path.join(self.img_path,self.img_name[idx]) label_path = os.path.join(self.label_path, self.label_name[idx]) img = Image.open (img_path) f = open (label_path) label = f.readline() f.close() return img,label def __len__ (self ): return len (self.img_name) root_dir = "new_data/train" ants_image_dir = "ants_image" ants_label_dir = "ants_label" bees_image_dir = "bees_image" bees_label_dir = "bees_label" ants_dataset = MyData(root_dir,ants_image_dir,ants_label_dir) bees_dataset = MyData(root_dir,bees_image_dir,bees_label_dir) train_dataset = ants_dataset + bees_dataset
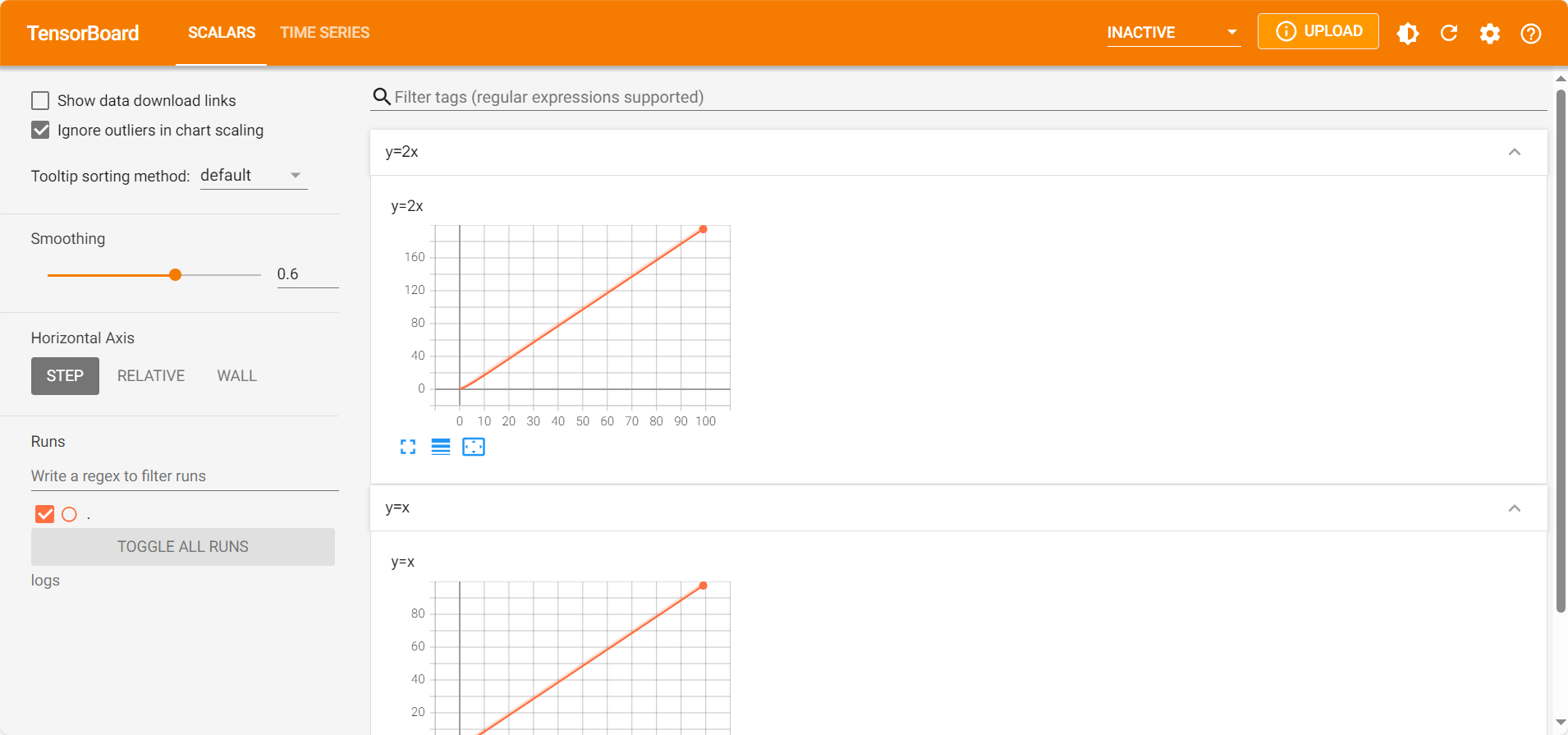
4.tensorboard的使用 1)SummaryWriter的使用 文件名不能是tensorboard.py
1 2 3 4 5 6 7 8 from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter("logs" ) for i in range (100 ): writer.add_scalar("y=x" , i, i) writer.close()
运行后代码相同文件夹下生成logs文件夹
控制台:
1 tensorboad --logdir=logs #logs可替换为其他存储日志文件的文件夹名称
如果改变图片的名称,会重新画一幅图,如果不改变图片的名称,会在上一幅图上画
解决方法:删掉原有log文件
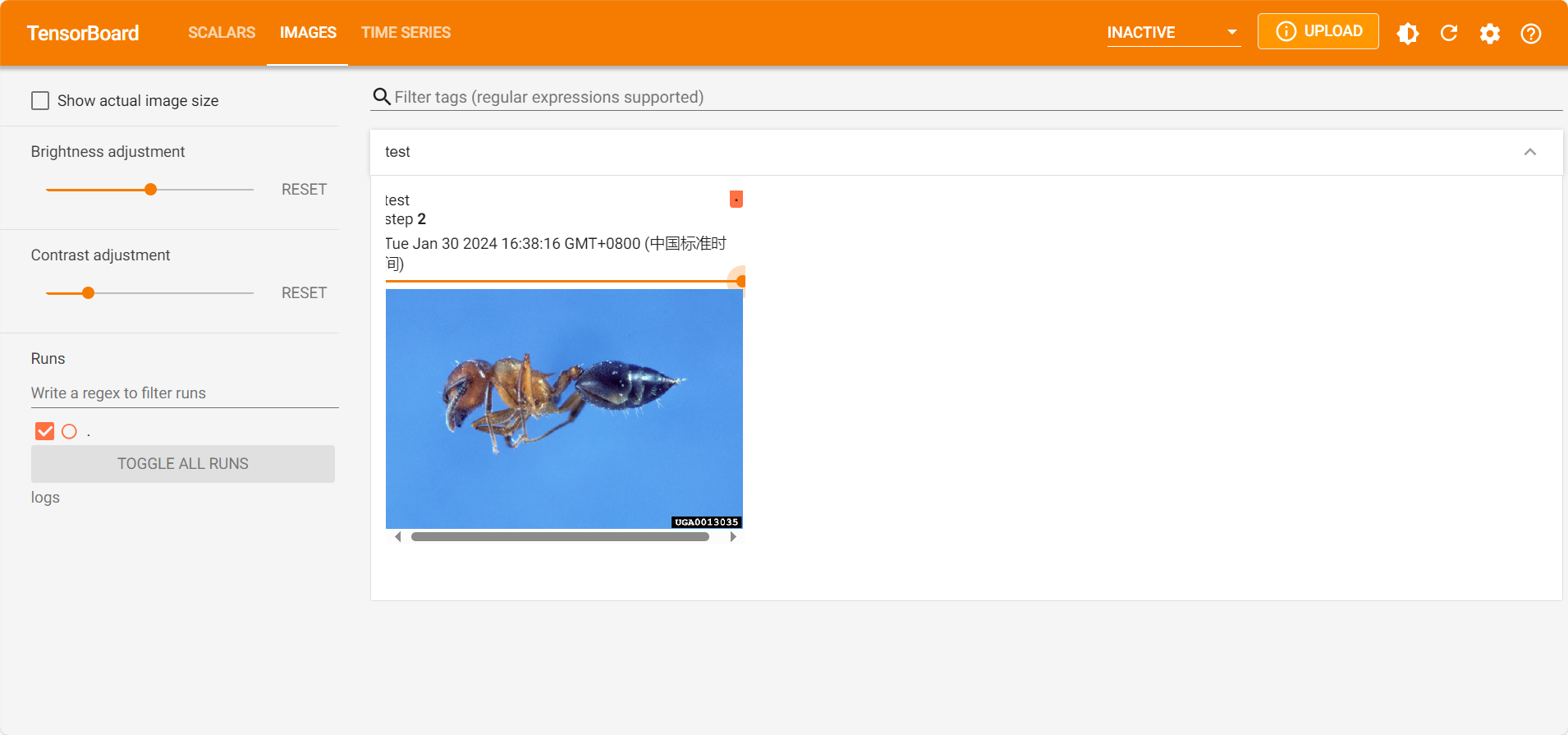
2)add_image的使用 add_image将图片在tensorboard中展示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from torch.utils.tensorboard import SummaryWriterimport numpy as npfrom PIL import Imagewriter = SummaryWriter("logs" ) image_path = "hymenoptera_data/train/ants/0013035.jpg" img_PIL = Image.open (image_path) img_array = np.array(img_PIL) print (type (img_array))print (img_array.shape)writer.add_image("test" ,img_array,2 ,dataformats='HWC' ) writer.close()
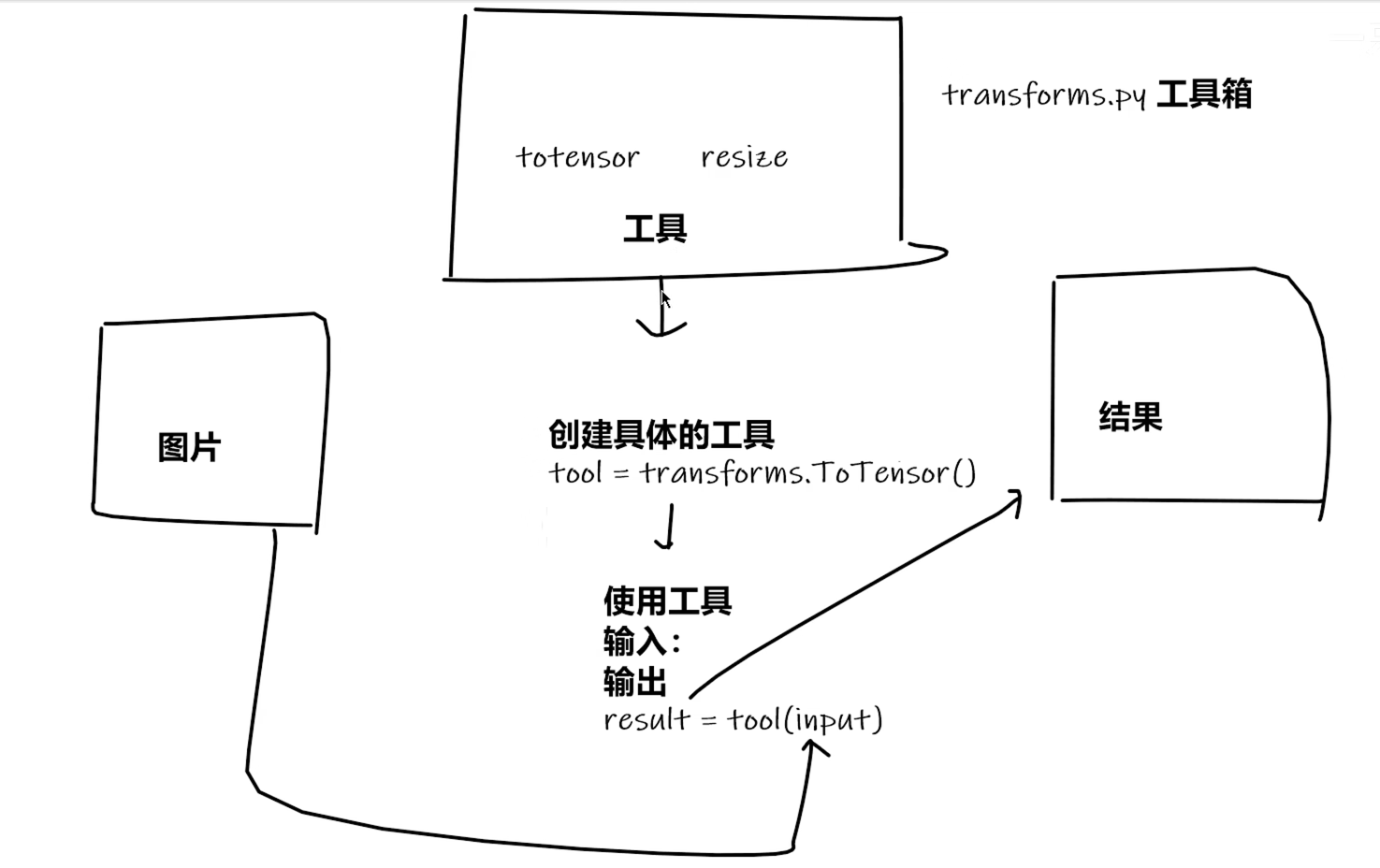
1)流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from PIL import Imagefrom torch.utils.tensorboard import SummaryWriterfrom torchvision import transformsimg_path = "hymenoptera_data/train/ants/0013035.jpg" img = Image.open (img_path) writer = SummaryWriter("logs" ) tensor_trans = transforms.ToTensor() tensor_img = tensor_trans(img) writer.add_image("img" ,tensor_img) writer.close()
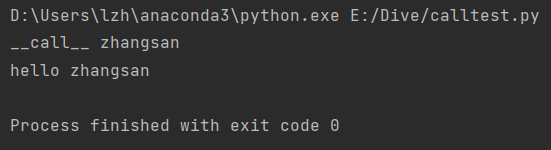
内置call (ctrl+p 提示参数)
1 2 3 4 5 6 7 8 9 10 class Person : def __call__ (self, name ): print ("__call__ " +name) def hello (self, name ): print ("hello " +name) person = Person() person("zhangsan" ) person.hello("zhangsan" )
transforms.Normalize
transforms.Resize
transforms.compose:组合多个操作
transforms.RandomCrop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 from PIL import Imagefrom torchvision import transformsfrom torch.utils.tensorboard import SummaryWriterimg_path = "hymenoptera_data/train/ants/0013035.jpg" img = Image.open (img_path) print (img)writer = SummaryWriter("logs" ) trans_totensor = transforms.ToTensor() img_tensor = trans_totensor(img) writer.add_image("img" , img_tensor, 0 ) trans_nore = transforms.Normalize([0.5 , 0.5 , 0.5 ], [0.5 , 0.5 , 0.5 ]) img_nore = trans_nore(img_tensor) writer.add_image("img" , img_nore, 1 ) print (img.size)trans_resize = transforms.Resize((512 ,512 )) img_resize = trans_resize(img) img_resize = trans_totensor(img_resize) writer.add_image("Resize" , img_resize, 0 ) print (img_resize)trans_resize_2 = transforms.Resize(512 ) trans_compose = transforms.Compose([trans_totensor, trans_resize_2]) img_resize_2 = trans_compose(img) writer.add_image("Resize" , img_resize_2, 1 ) trans_random = transforms.RandomCrop((500 , 500 )) trans_compose_2 = transforms.Compose([trans_random, trans_totensor]) for i in range (10 ): img_crop = trans_compose_2(img) writer.add_image("RandomCrop" , img_crop, i) writer.close()
6.数据集的使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import torchvisionfrom torchvision import transformsfrom torch.utils.tensorboard import SummaryWriterdataset_transform = transforms.Compose([ transforms.ToTensor() ]) train_set = torchvision.datasets.CIFAR10("./dataset" , train=True , transform=dataset_transform, download=True ) test_set = torchvision.datasets.CIFAR10("./dataset" , train=False , transform=dataset_transform, download=False ) writer = SummaryWriter("p10" ) for i in range (10 ): img, target = test_set[i] writer.add_image("test_set" ,img,i) writer.close()
如果下载不成功,通过迅雷等其他方式下载,建立dataset文件夹并将压缩文件直接放到dataset文件夹下,运行代码会自动解压
7.Dataloader的使用 dataloader从dataset中取数据打包,以便送入神经网络
torch.utils.data.DataLoader()
batch_size 表示每次多少个batch_size打成一包
shuffle 表示是否打乱顺序(每次for data in loader时是否打乱顺序,而不是说打包是否随机取,默认就是随机取的)
drop_last 当data/batch_size除不尽要不要舍去剩下的data
numofworks 设置为0表示用主进程加载,Windows下设置为其他值可能出错
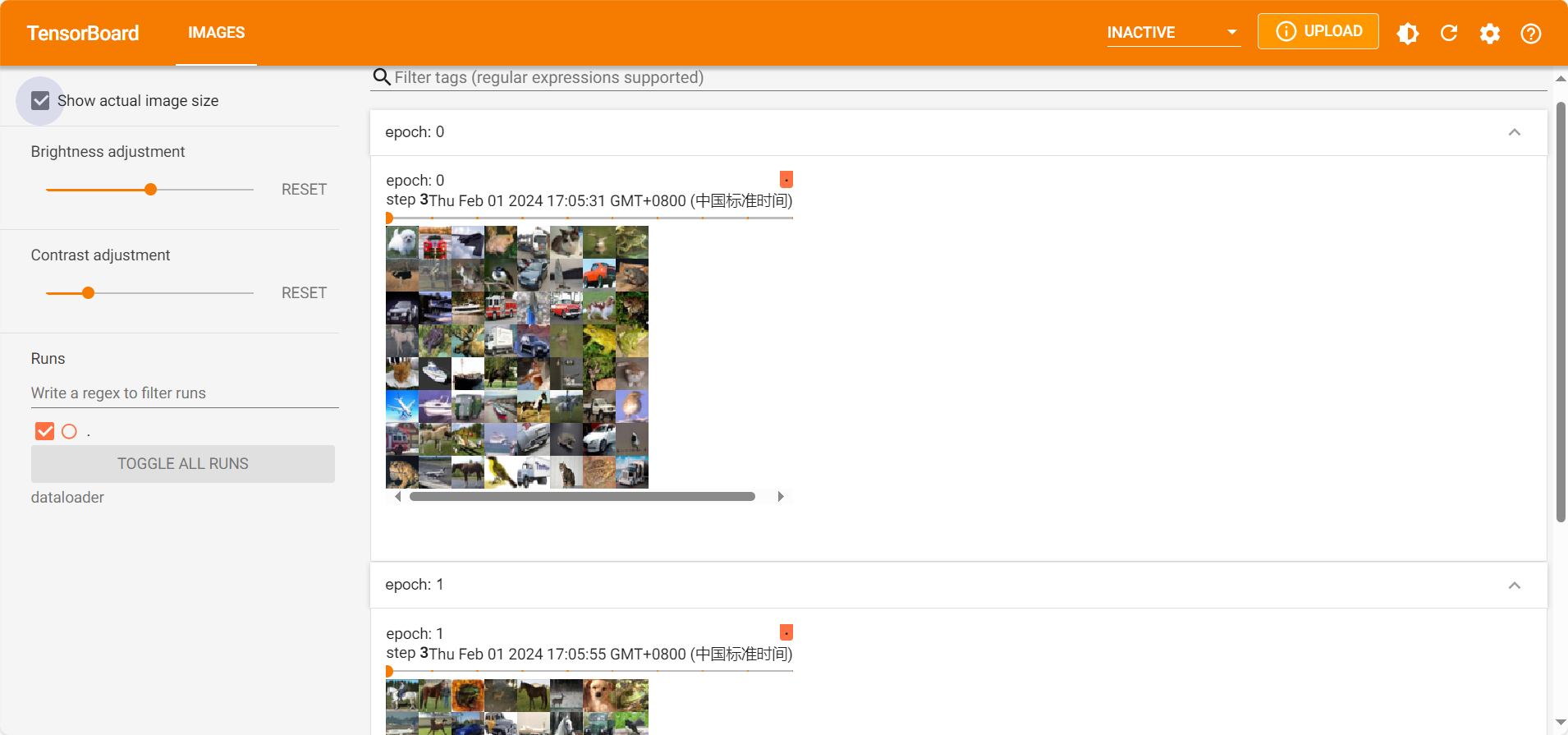
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import torchvisionfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWritertest_data = torchvision.datasets.CIFAR10("./dataset" , train=False , transform=torchvision.transforms.ToTensor()) test_loader = DataLoader(dataset=test_data, batch_size=64 , shuffle=True , num_workers=0 , drop_last=True ) img, target =test_data[0 ] print (img.shape) print (target) writer = SummaryWriter("dataloader" ) for epoch in range (2 ): step = 0 for data in test_loader: imgs , targets = data writer.add_images("epoch: {}" .format (epoch), imgs, step) step = step + 1 writer.close()
8. torch.nn nn.module:Base class for all neural network modules.
所有神经网络模型都要继承nn.module
神经网络运行于forward函数之中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import torchfrom torch import nnclass Tudui (nn.Module): def __init__ (self ): super (Tudui, self).__init__() def forward (self, input ): output = input + 1 return output tudui =Tudui() x = torch.tensor(1.0 ) output = tudui(x) print (output)
pycharm的断点调试
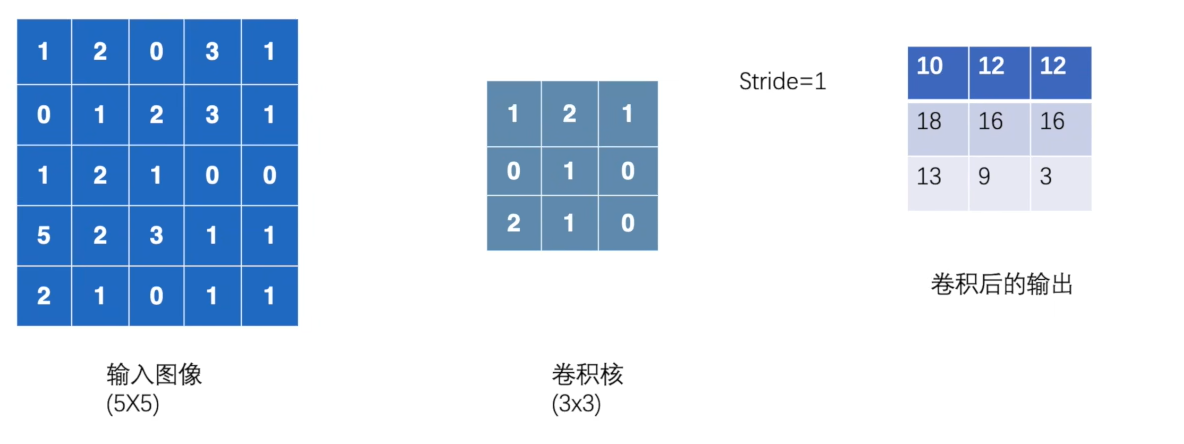
9.卷积操作
torch.nn.functional.conv2d(input , weight , bias=None , stride=1 , padding=0 , dilation=1 , groups=1 )
stride:卷积核移动的步长
padding:输入图像是否填充
weight:卷积核
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import torchimport torch.nn.functional as Finput = torch.tensor([[1 , 2 , 0 , 3 , 1 ], [0 , 1 , 2 , 3 , 1 ], [1 , 2 , 1 , 0 , 0 ], [5 , 2 , 3 , 1 , 1 ], [2 , 1 , 0 , 1 , 1 ]]) kernel = torch.tensor([[1 , 2 , 1 ], [0 , 1 , 0 ], [2 , 1 , 0 ]]) input = torch.reshape(input , (1 , 1 , 5 , 5 ))kernel = torch.reshape(kernel, (1 , 1 , 3 , 3 )) print (input .shape)print (kernel.shape)output = F.conv2d(input , kernel, stride=1 ) print (output)output2 = F.conv2d(input , kernel, stride=2 ) print (output2)output3 = F.conv2d(input , kernel, stride=1 , padding=1 ) print (output3)
10.神经网络 卷积层
torch.nn.Conv2d(in_channels , out_channels , kernel_size , stride=1 , padding=0 , dilation=1 , groups=1 , bias=True , padding_mode=’zeros’ , device=None , dtype=None )
in_channels:输入通道数
out_channels:卷积层内部可通过增加卷积核数量来增加通道数
kernel_size:只需要设置kernel_size,参数训练中调整
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import torchimport torchvisionfrom torch import nnfrom torch.nn import Conv2dfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("./dataset" ,train=False ,transform=torchvision.transforms.ToTensor(),download=True ) dataloader = DataLoader(dataset, batch_size=64 ) class Tudui (nn.Module): def __init__ (self ): super (Tudui, self).__init__() self.conv1 = Conv2d(in_channels=3 , out_channels=6 , kernel_size=3 , stride=1 , padding=0 ) def forward (self,x ): x = self.conv1(x) return x tudui = Tudui() writer = SummaryWriter("logs" ) step = 0 for data in dataloader: imgs, targets = data output = tudui(imgs) writer.add_images("input" , imgs, step) output = torch.reshape(output, (-1 , 3 , 30 , 30 )) writer.add_images("output" , output, step) step = step + 1 writer.close()
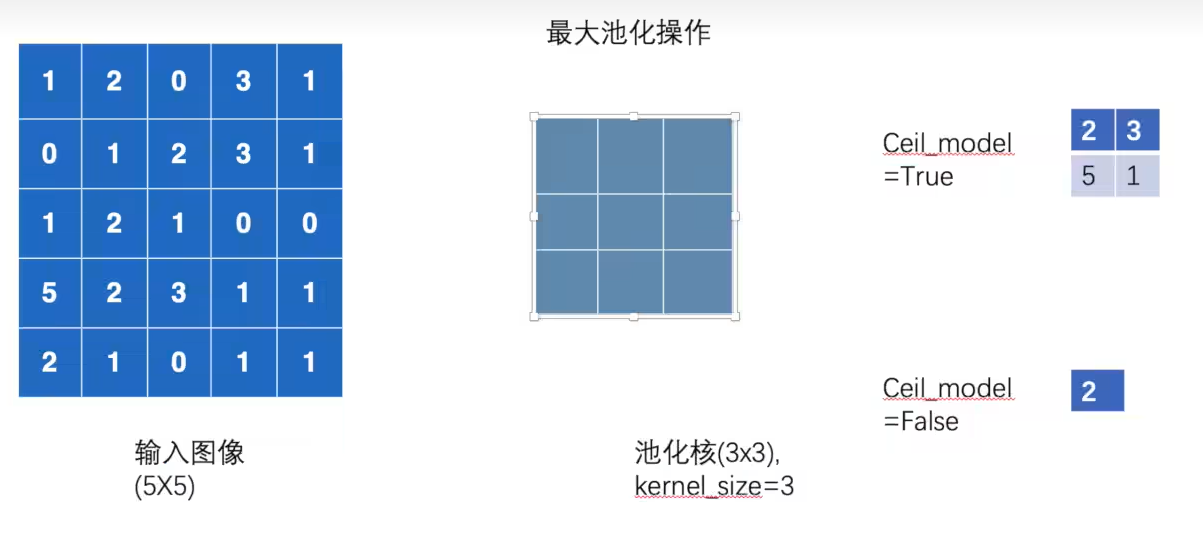
池化层
池化的作用是减少参数量,下采样
池化层的stride默认是池化核的size
ceil_model为true表示当输入图片不足池化核时仍然进行池化,false表示不进行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from torch import nnimport torchimport torchvisionfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriterclass Tudui (nn.Module): def __init__ (self ): super (Tudui, self).__init__() self.maxpool1 = nn.MaxPool2d(kernel_size=3 ,ceil_mode=True ) def forward (self, input ): output = self.maxpool1(input ) return output dataset = torchvision.datasets.CIFAR10("dataset" , train=False , transform=torchvision.transforms.ToTensor(), download=True ) dataloader = DataLoader(dataset, batch_size=64 ) writer = SummaryWriter("maxpool" ) tudui = Tudui() step = 0 for data in dataloader: imgs, targets = data writer.add_images("imgs" , imgs, step) output = tudui(imgs) writer.add_images("output" , output, step) step = step + 1 writer.close()
非线性激活 引入非线性特征。relu、sigmoid
参数 inplace:一般inplace为false不覆盖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import torchfrom torch import nnimport torchvisionfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriterclass Tudui (nn.Module): def __init__ (self ): super (Tudui, self).__init__() self.relu = nn.ReLU(inplace=False ) def forward (self,input ): output = self.relu(input ) return output dataset = torchvision.datasets.CIFAR10("./dataset" ,train=False ,transform=torchvision.transforms.ToTensor(),download=True ) dataloader = DataLoader(dataset,batch_size=64 ) tudui = Tudui() writer = SummaryWriter("relu" ) step = 0 for data in dataloader: imgs, targets = data writer.add_images("input" , imgs, step) output = tudui(imgs) writer.add_images("output" , output, step) step = step + 1 writer.close()
线性层和其他层 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import torchfrom torch import nnimport torchvisionfrom torch.utils.data import DataLoaderclass Tudui (nn.Module): def __init__ (self ): super (Tudui, self).__init__() self.linear = nn.Linear(196608 ,10 ) def forward (self, input ): output = self.linear(input ) return output dataset = torchvision.datasets.CIFAR10("./dataset" ,train=False ,transform=torchvision.transforms.ToTensor(),download=True ) dataloader = DataLoader(dataset, batch_size=64 , drop_last=True ) tudui = Tudui() for data in dataloader: imgs, targets = data output = torch.flatten(imgs) output = tudui(output) print (output.shape)
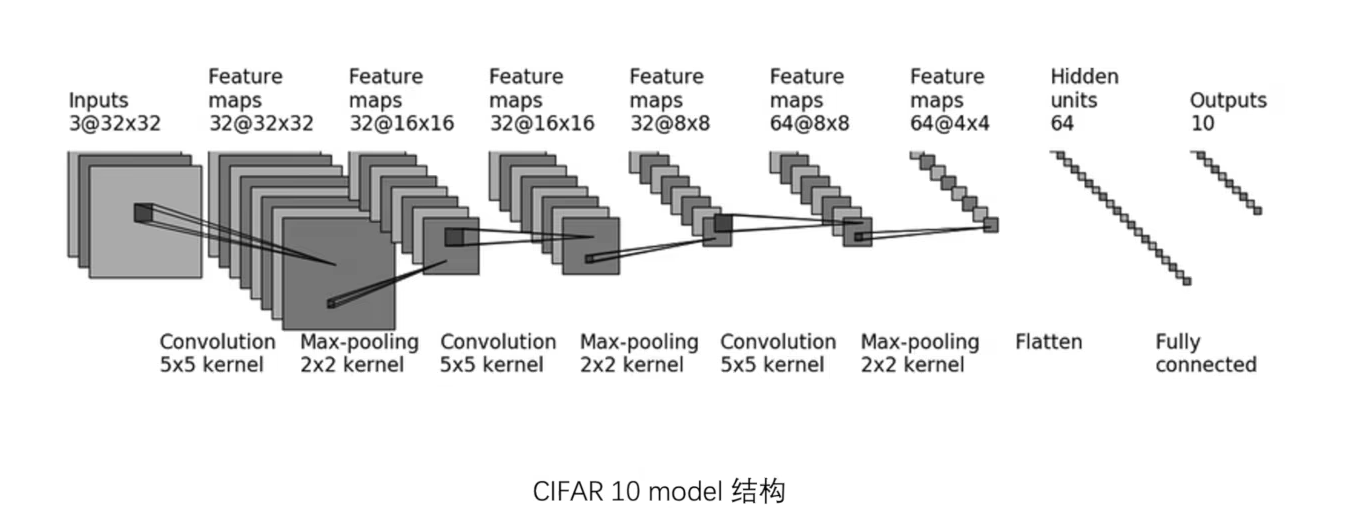
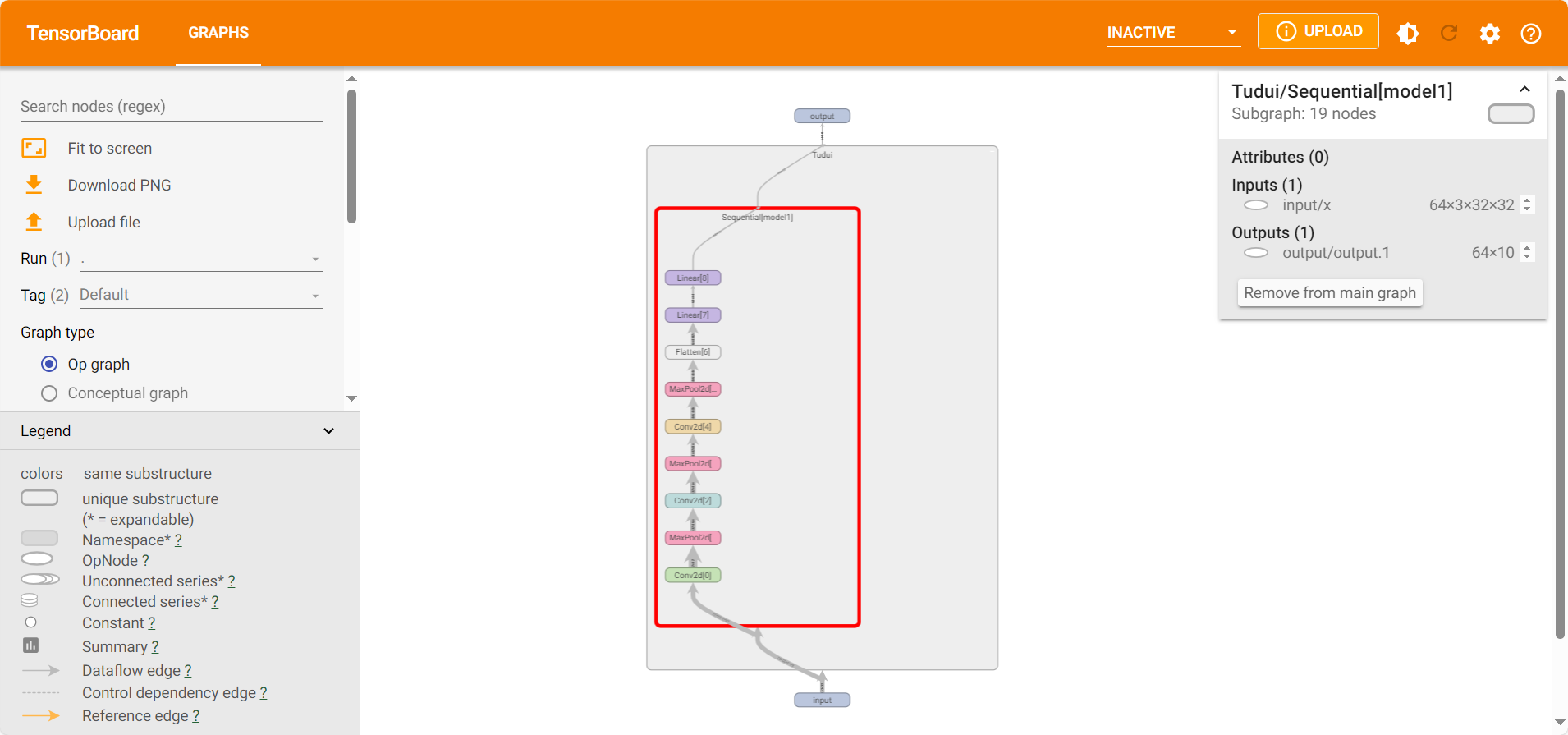
sequential的使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import torchfrom torch import nnfrom torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linearfrom torch.utils.tensorboard import SummaryWriterclass Tudui (nn.Module): def __init__ (self ): super (Tudui, self).__init__() self.model1 = Sequential( Conv2d(3 , 32 , 5 , padding=2 ), MaxPool2d(2 ), Conv2d(32 , 32 , 5 , padding=2 ), MaxPool2d(2 ), Conv2d(32 , 64 , 5 , padding=2 ), MaxPool2d(2 ), Flatten(), Linear(1024 , 64 ), Linear(64 , 10 ) ) def forward (self, x ): x = self.model1(x) return x tudui = Tudui() print (tudui)input = torch.ones((64 , 3 , 32 , 32 ))output = tudui(input ) print (output.shape)writer = SummaryWriter("seq" ) writer.add_graph(tudui, input ) writer.close()
损失函数与反向传播 loss计算output和target之间的差距,loss越小越好,loss作为反向传播的依据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import torchimport torchvisionfrom torch import nnfrom torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linearfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriterclass Tudui (nn.Module): def __init__ (self ): super (Tudui, self).__init__() self.model1 = Sequential( Conv2d(3 , 32 , 5 , padding=2 ), MaxPool2d(2 ), Conv2d(32 , 32 , 5 , padding=2 ), MaxPool2d(2 ), Conv2d(32 , 64 , 5 , padding=2 ), MaxPool2d(2 ), Flatten(), Linear(1024 , 64 ), Linear(64 , 10 ) ) def forward (self, x ): x = self.model1(x) return x dataset = torchvision.datasets.CIFAR10("./dataset" ,train=False ,transform=torchvision.transforms.ToTensor(),download=True ) dataloader = DataLoader(dataset, batch_size=64 ) loss = nn.CrossEntropyLoss() tudui = Tudui() for data in dataloader: imgs, targets = data output = tudui(imgs) result_loss = loss(output, targets) print (result_loss) input ()
优化器 lr:学习速率
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import torchimport torchvisionfrom torch import nnfrom torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linearfrom torch.utils.data import DataLoaderfrom torch.utils.tensorboard import SummaryWriterclass Tudui (nn.Module): def __init__ (self ): super (Tudui, self).__init__() self.model1 = Sequential( Conv2d(3 , 32 , 5 , padding=2 ), MaxPool2d(2 ), Conv2d(32 , 32 , 5 , padding=2 ), MaxPool2d(2 ), Conv2d(32 , 64 , 5 , padding=2 ), MaxPool2d(2 ), Flatten(), Linear(1024 , 64 ), Linear(64 , 10 ) ) def forward (self, x ): x = self.model1(x) return x dataset= torchvision.datasets.CIFAR10("./dataset" ,train=False ,transform=torchvision.transforms.ToTensor(), download=True ) dataloader = DataLoader(dataset, batch_size=64 ) loss = nn.CrossEntropyLoss() tudui = Tudui() optim = torch.optim.SGD(tudui.parameters(), lr=0.01 ) for epoch in range (20 ): running_loss = 0.0 for data in dataloader: imgs, targets = data output = tudui(imgs) result_loss = loss(output, targets) optim.zero_grad() result_loss.backward() optim.step() running_loss = running_loss + result_loss print (running_loss)
现有模型的修改与使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import torchvisionfrom torch import nnvgg16_false = torchvision.models.vgg16(pretrained=False ) vgg16_true = torchvision.models.vgg16(pretrained=True ) print (vgg16_true)train_data = torchvision.datasets.CIFAR10('../data' , train=True , transform=torchvision.transforms.ToTensor(), download=True ) vgg16_true.classifier.add_module('add_linear' , nn.Linear(1000 , 10 )) print (vgg16_true)print (vgg16_false)vgg16_false.classifier[6 ] = nn.Linear(4096 , 10 ) print (vgg16_false)
11.完整训练套路 CPU:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 import torchimport torchvisionfrom torch.utils.tensorboard import SummaryWriterfrom model import *from torch import nnfrom torch.utils.data import DataLoadertrain_data = torchvision.datasets.CIFAR10(root="./dataset" , train=True , transform=torchvision.transforms.ToTensor(), download=True ) test_data = torchvision.datasets.CIFAR10(root="./dataset" , train=False , transform=torchvision.transforms.ToTensor(), download=True ) train_data_size = len (train_data) test_data_size = len (test_data) print ("训练数据集的长度为:{}" .format (train_data_size))print ("测试数据集的长度为:{}" .format (test_data_size))train_dataloader = DataLoader(train_data, batch_size=64 ) test_dataloader = DataLoader(test_data, batch_size=64 ) tudui = Tudui() loss_fn = nn.CrossEntropyLoss() learning_rate = 0.01 optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate) total_train_step = 0 total_test_step = 0 epoch = 10 writer = SummaryWriter("logs_train" ) for i in range (epoch): print ("--------第{}轮训练开始--------" .format (i)) for data in train_dataloader: imgs, targets = data output = tudui(imgs) loss = loss_fn(output, targets) optimizer.zero_grad() loss.backward() optimizer.step() total_train_step = total_train_step + 1 if total_train_step % 100 == 0 : print ("训练次数: {}, Loss: {}" .format (total_train_step,loss.item())) writer.add_scalar("train_loss" ,loss.item(),total_train_step) tudui.eval () total_test_loss = 0 total_accuracy = 0 with torch.no_grad(): for data in test_dataloader: imgs, targets = data outputs = tudui(imgs) loss = loss_fn(outputs, targets) total_test_loss = total_test_loss + loss.item() accuracy = (outputs.argmax(1 ) == targets).sum () total_accuracy = total_accuracy + accuracy print ("整体测试集上的Loss: {}" .format (total_test_loss)) print ("整体测试集上的正确率: {}" .format (total_accuracy / test_data_size)) writer.add_scalar("test_loss" , total_test_loss, total_test_step) writer.add_scalar("test_accuracy" , total_accuracy / test_data_size, total_test_step) total_test_step = total_test_step + 1 torch.save(tudui, "tudui_{}.pth" .format (i)) print ("模型已保存" ) writer.close()
12. 利用GPU训练 方法一:调用 网络模型、数据(输入、标注)、损失函数的 cuda方法
1 2 if torch.cuda.is_available(): xxx
GPU版:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 import torchimport torchvisionfrom torch.utils.tensorboard import SummaryWriterfrom model import *from torch import nnfrom torch.utils.data import DataLoadertrain_data = torchvision.datasets.CIFAR10(root="./dataset" , train=True , transform=torchvision.transforms.ToTensor(), download=True ) test_data = torchvision.datasets.CIFAR10(root="./dataset" , train=False , transform=torchvision.transforms.ToTensor(), download=True ) train_data_size = len (train_data) test_data_size = len (test_data) print ("训练数据集的长度为:{}" .format (train_data_size))print ("测试数据集的长度为:{}" .format (test_data_size))train_dataloader = DataLoader(train_data, batch_size=64 ) test_dataloader = DataLoader(test_data, batch_size=64 ) tudui = Tudui() if torch.cuda.is_available(): tudui = tudui.cuda() print ("yes" ) loss_fn = nn.CrossEntropyLoss() if torch.cuda.is_available(): loss_fn = loss_fn.cuda() learning_rate = 0.01 optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate) total_train_step = 0 total_test_step = 0 epoch = 10 writer = SummaryWriter("logs_train" ) for i in range (epoch): print ("--------第{}轮训练开始--------" .format (i)) for data in train_dataloader: imgs, targets = data if torch.cuda.is_available(): targets = targets.cuda() imgs = imgs.cuda() output = tudui(imgs) loss = loss_fn(output, targets) optimizer.zero_grad() loss.backward() optimizer.step() total_train_step = total_train_step + 1 if total_train_step % 100 == 0 : print ("训练次数: {}, Loss: {}" .format (total_train_step,loss.item())) writer.add_scalar("train_loss" ,loss.item(),total_train_step) tudui.eval () total_test_loss = 0 total_accuracy = 0 with torch.no_grad(): for data in test_dataloader: imgs, targets = data if torch.cuda.is_available(): targets = targets.cuda() imgs = imgs.cuda() outputs = tudui(imgs) loss = loss_fn(outputs, targets) total_test_loss = total_test_loss + loss.item() accuracy = (outputs.argmax(1 ) == targets).sum () total_accuracy = total_accuracy + accuracy print ("整体测试集上的Loss: {}" .format (total_test_loss)) print ("整体测试集上的正确率: {}" .format (total_accuracy / test_data_size)) writer.add_scalar("test_loss" , total_test_loss, total_test_step) writer.add_scalar("test_accuracy" , total_accuracy / test_data_size, total_test_step) total_test_step = total_test_step + 1 torch.save(tudui, "tudui_{}.pth" .format (i)) print ("模型已保存" ) writer.close()
方法二:
首先创建device,然后调用 网络模型、数据(输入、标注)、损失函数 的to方法
1 2 3 torch.device("cuda" ) torch.device("cpu" ) device = torch.device("cuda" if torch.cuda.is_available() else "cpu" )
GPU版:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 import torchimport torchvisionfrom torch.utils.tensorboard import SummaryWriterfrom model import *from torch import nnfrom torch.utils.data import DataLoaderdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu" ) train_data = torchvision.datasets.CIFAR10(root="./dataset" , train=True , transform=torchvision.transforms.ToTensor(), download=True ) test_data = torchvision.datasets.CIFAR10(root="./dataset" , train=False , transform=torchvision.transforms.ToTensor(), download=True ) train_data_size = len (train_data) test_data_size = len (test_data) print ("训练数据集的长度为:{}" .format (train_data_size))print ("测试数据集的长度为:{}" .format (test_data_size))train_dataloader = DataLoader(train_data, batch_size=64 ) test_dataloader = DataLoader(test_data, batch_size=64 ) tudui = Tudui() tudui = tudui.to(device) loss_fn = nn.CrossEntropyLoss() loss_fn = loss_fn.to(device) learning_rate = 0.01 optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate) total_train_step = 0 total_test_step = 0 epoch = 10 writer = SummaryWriter("logs_train" ) for i in range (epoch): print ("--------第{}轮训练开始--------" .format (i)) for data in train_dataloader: imgs, targets = data targets = targets.to(device) imgs = imgs.to(device) output = tudui(imgs) loss = loss_fn(output, targets) optimizer.zero_grad() loss.backward() optimizer.step() total_train_step = total_train_step + 1 if total_train_step % 100 == 0 : print ("训练次数: {}, Loss: {}" .format (total_train_step,loss.item())) writer.add_scalar("train_loss" ,loss.item(),total_train_step) tudui.eval () total_test_loss = 0 total_accuracy = 0 with torch.no_grad(): for data in test_dataloader: imgs, targets = data targets = targets.to(device) imgs = imgs.to(device) outputs = tudui(imgs) loss = loss_fn(outputs, targets) total_test_loss = total_test_loss + loss.item() accuracy = (outputs.argmax(1 ) == targets).sum () total_accuracy = total_accuracy + accuracy print ("整体测试集上的Loss: {}" .format (total_test_loss)) print ("整体测试集上的正确率: {}" .format (total_accuracy / test_data_size)) writer.add_scalar("test_loss" , total_test_loss, total_test_step) writer.add_scalar("test_accuracy" , total_accuracy / test_data_size, total_test_step) total_test_step = total_test_step + 1 torch.save(tudui, "tudui_{}.pth" .format (i)) print ("模型已保存" ) writer.close()
13.模型验证 1 2 3 4 5 6 tudui = torch.load("tudui_9.pth" , map_location=torch.device('cpu' )) ... tudui.eval () with torch.no_grad():
test.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import torchimport torchvisionfrom PIL import Imagefrom torch import nnfrom model import *image_path = "dataset/dog.jpg" image = Image.open (image_path) print (image)image = image.convert('RGB' ) transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32 ,32 )), torchvision.transforms.ToTensor()]) image = transform(image) print (image)tudui = torch.load("tudui_9.pth" , map_location=torch.device('cpu' )) print (tudui)image = torch.reshape(image, (1 , 3 , 32 , 32 )) tudui.eval () with torch.no_grad(): output = tudui(image) print (output)print (output.argmax(1 ))
pytorch入门部分 完结撒花😊