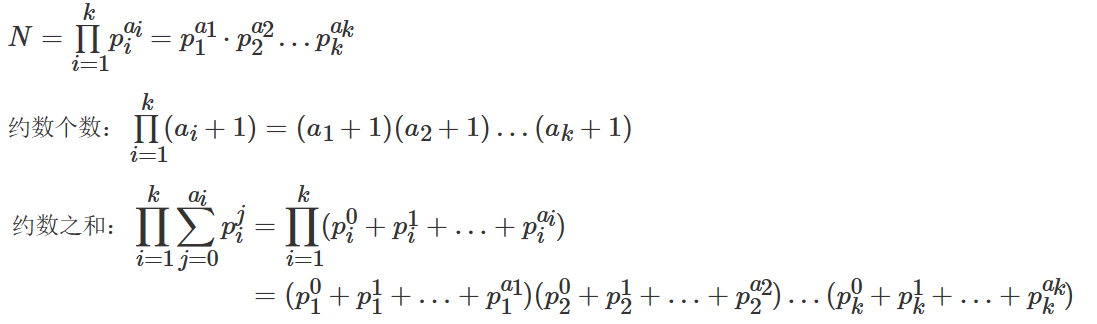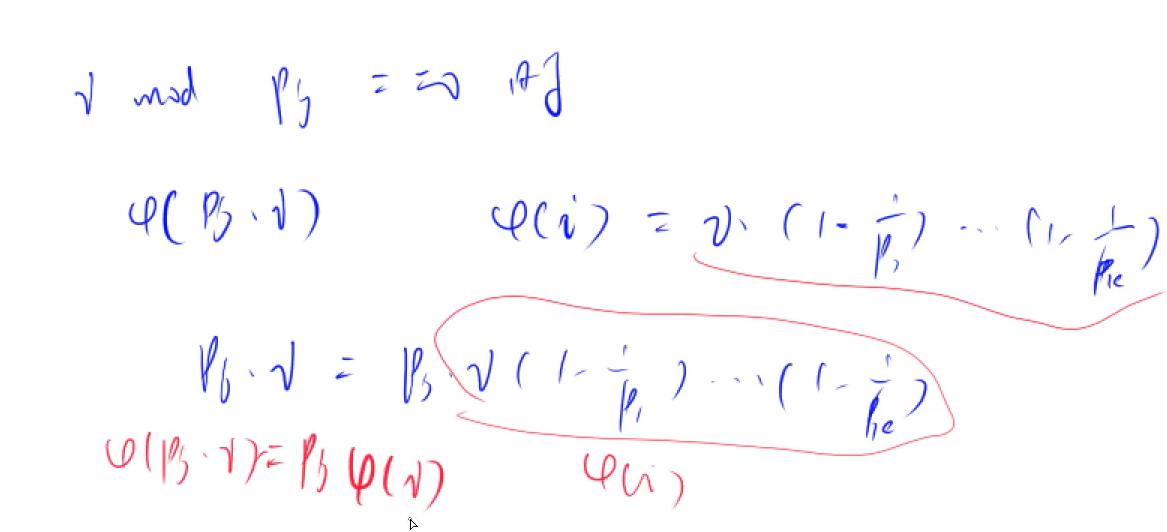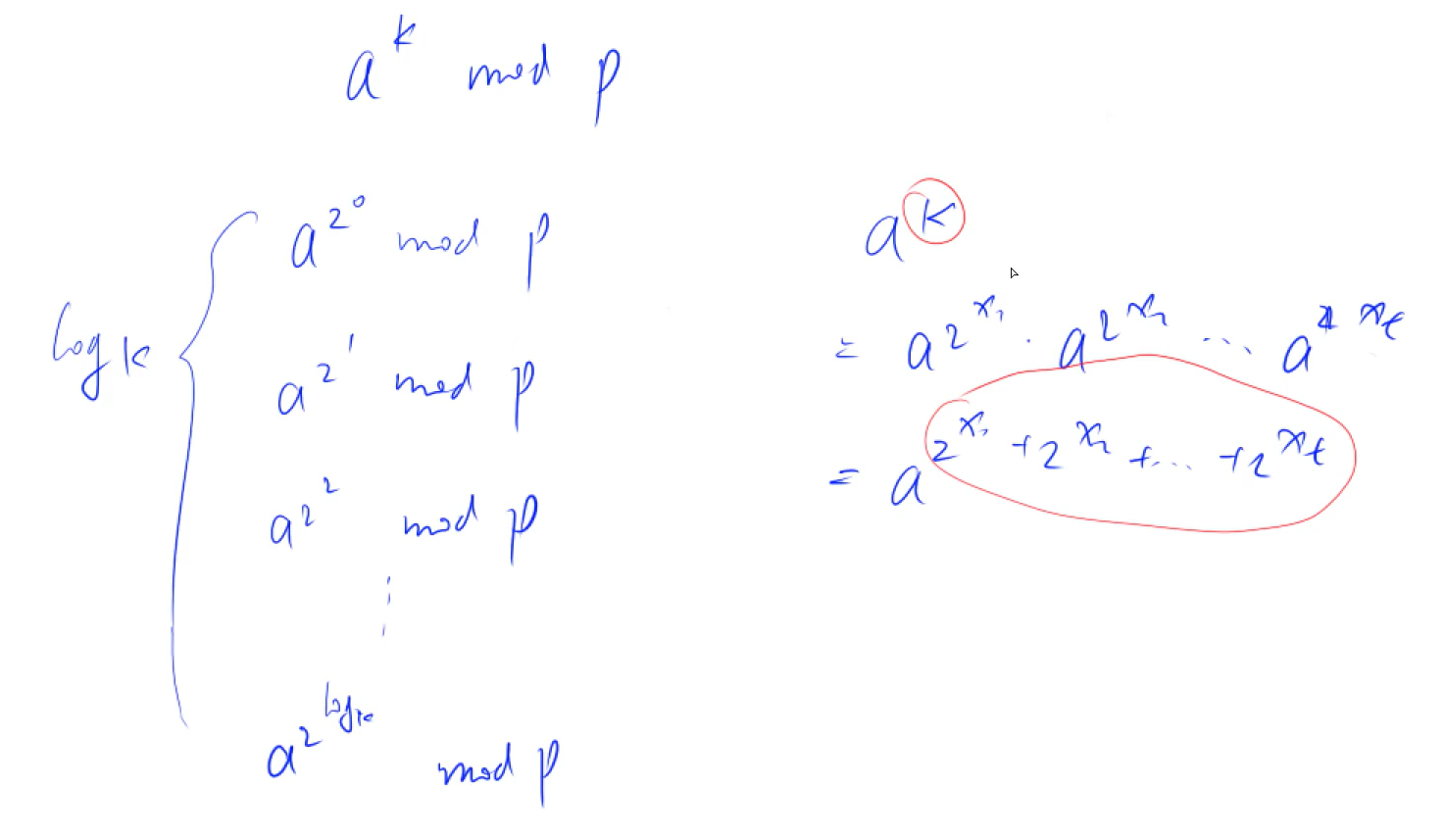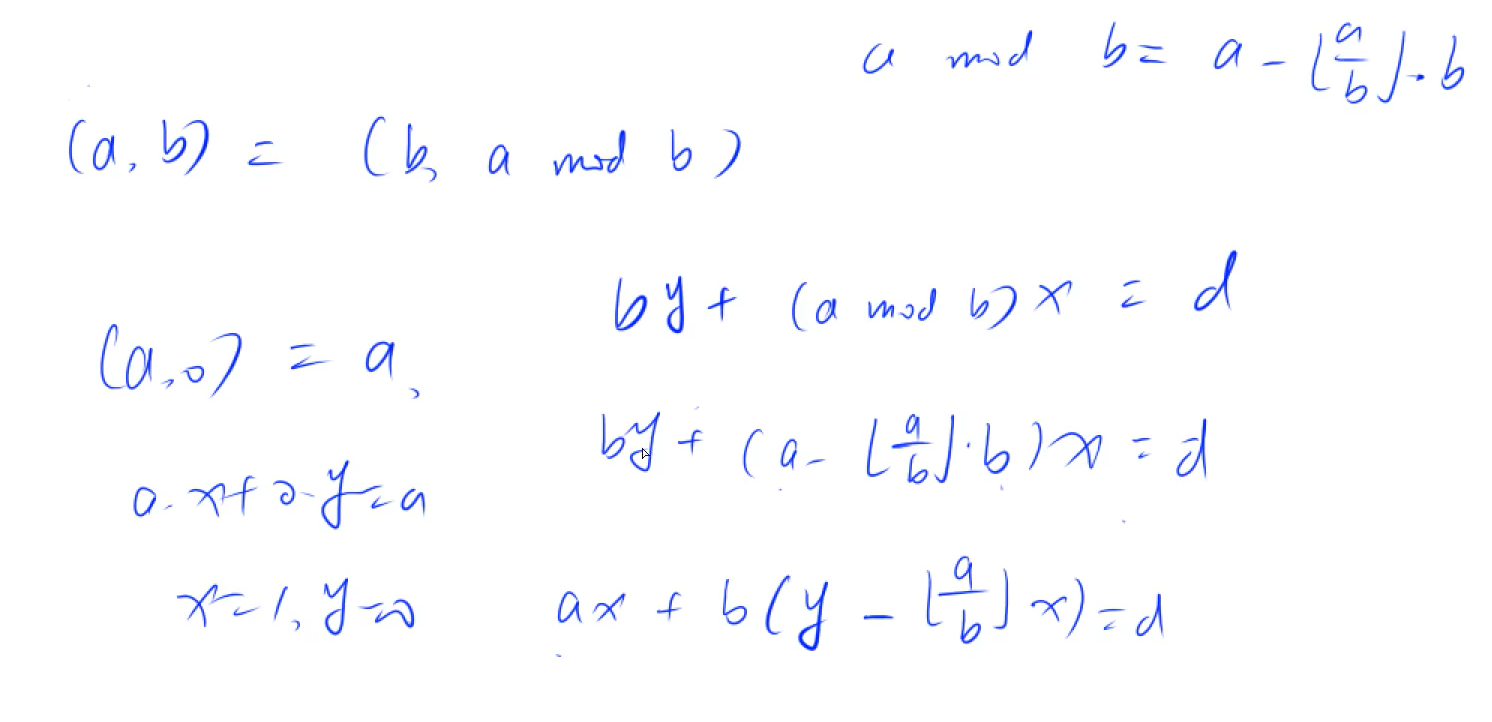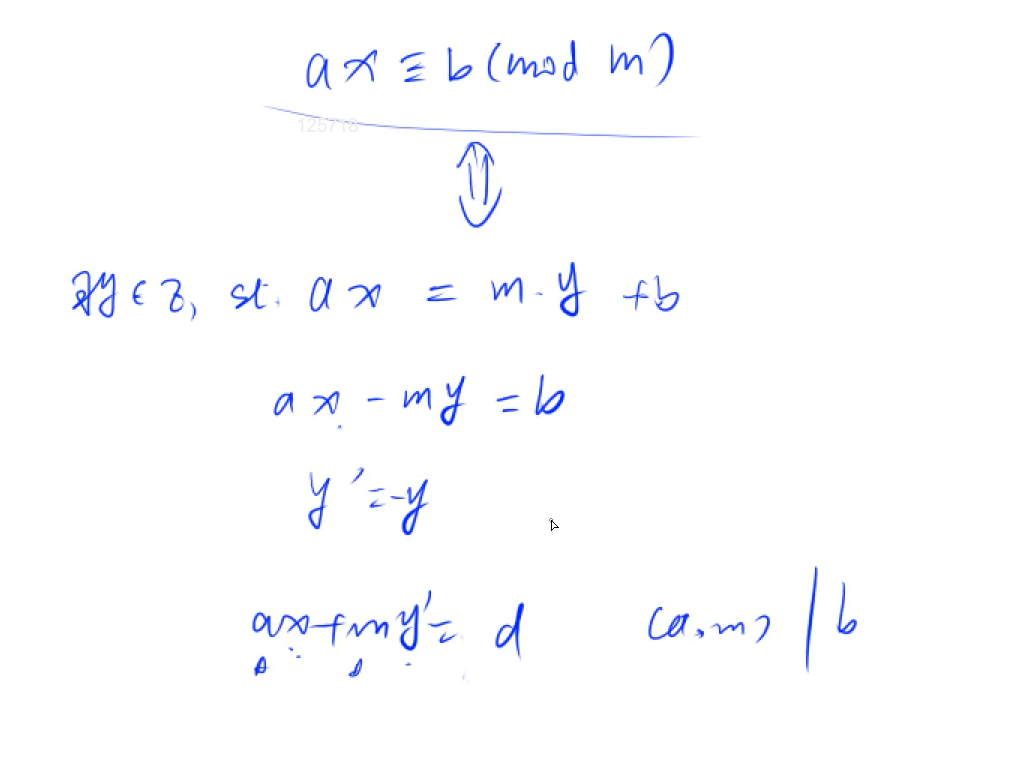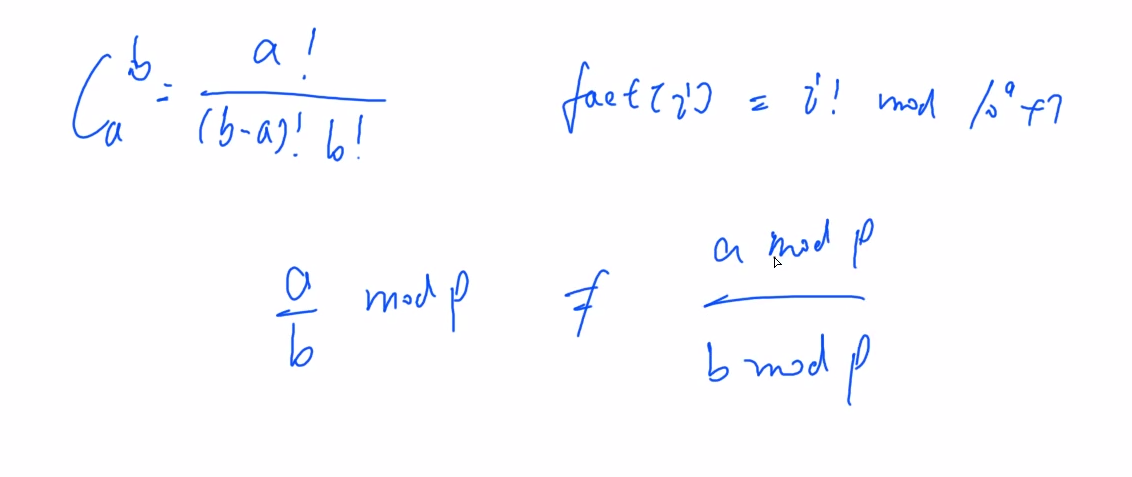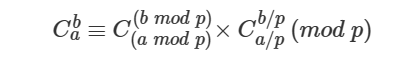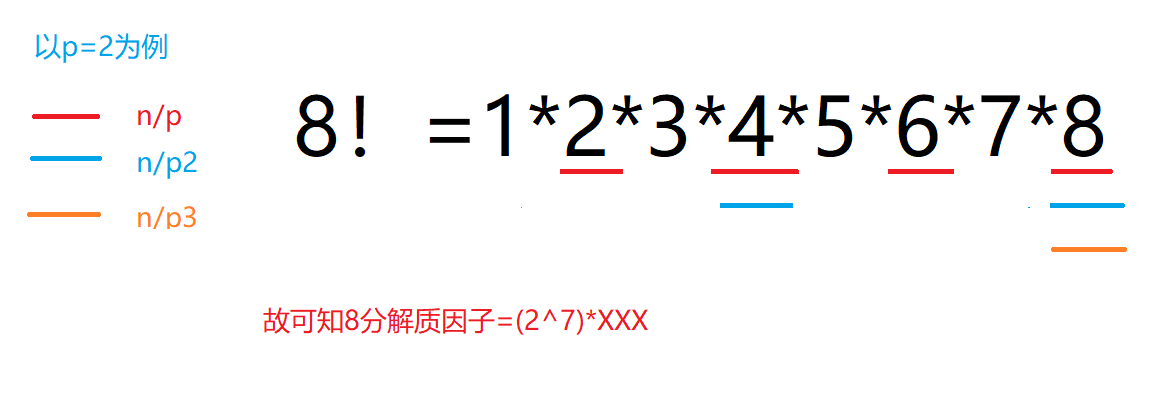tips
c++里面1e7和1e8的复杂度大概1s能够计算得到
10的9次方以内或者32位整数用int存放,10的18次方以内或者64位整数用long long 存放
小写字母比大写字母的ASCII大32
%d-整数;%s-字符串(字符数组),%f-浮点数,%c-char
对于四舍五入的处理:可以直接进行判断,也可以使用浮点数的round函数
自建数据结构一定要考虑初始化
C++位运算的优先级比加减乘除的优先级低,所以遇到位运算和加减乘除一起的,要加个括号。
注意要不要用long long
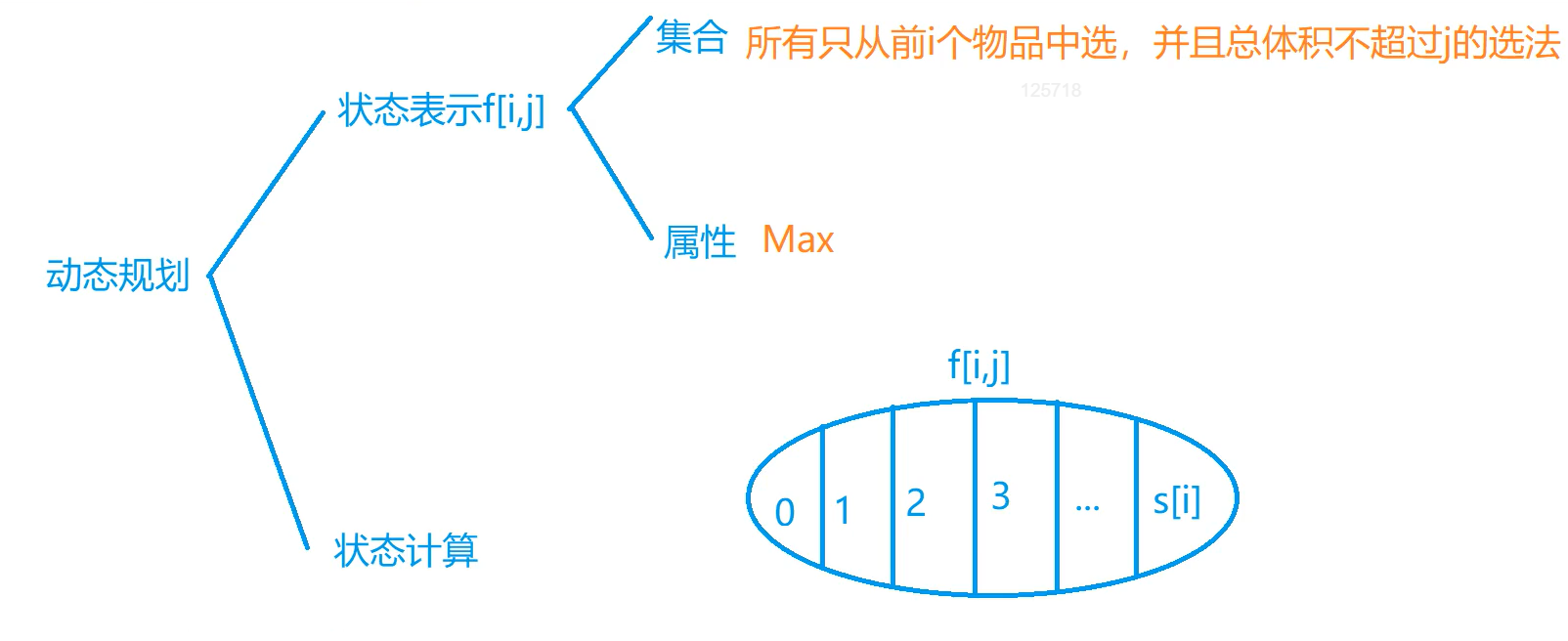
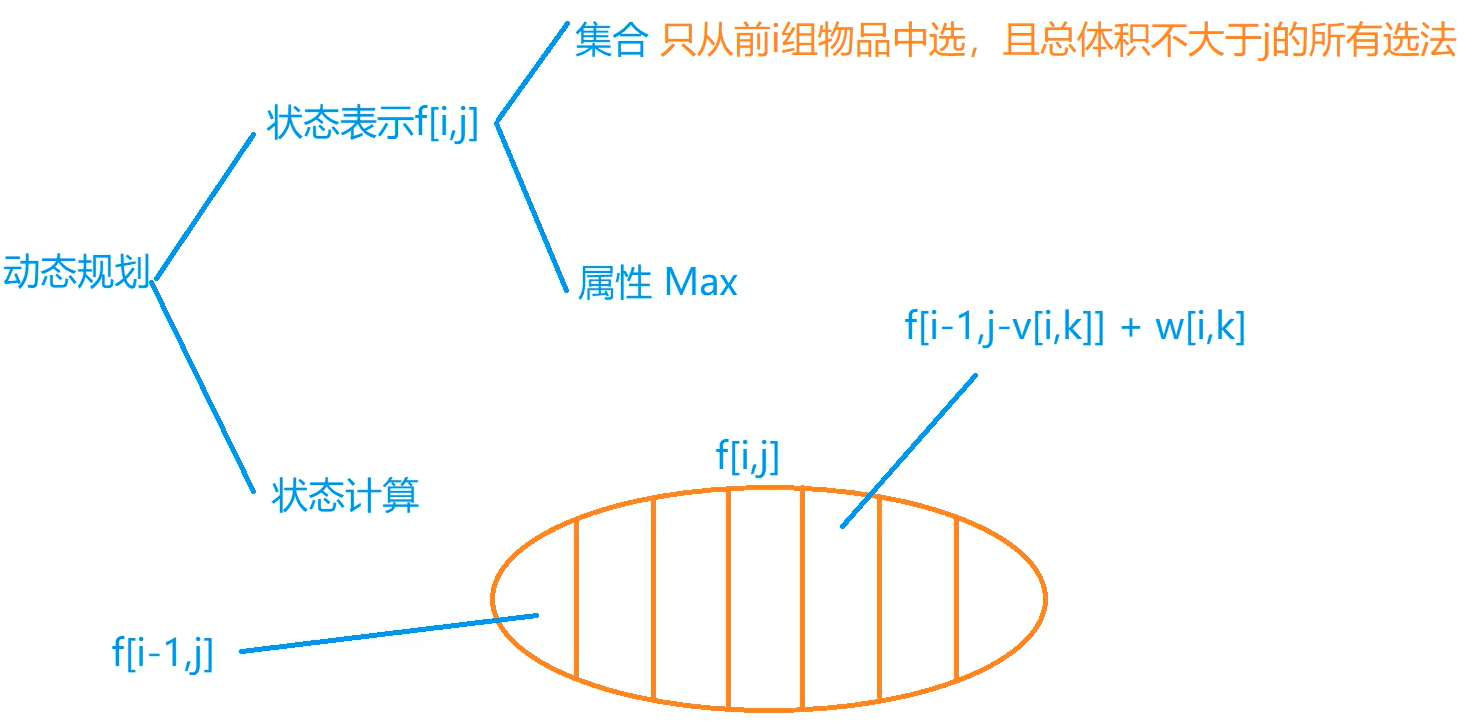
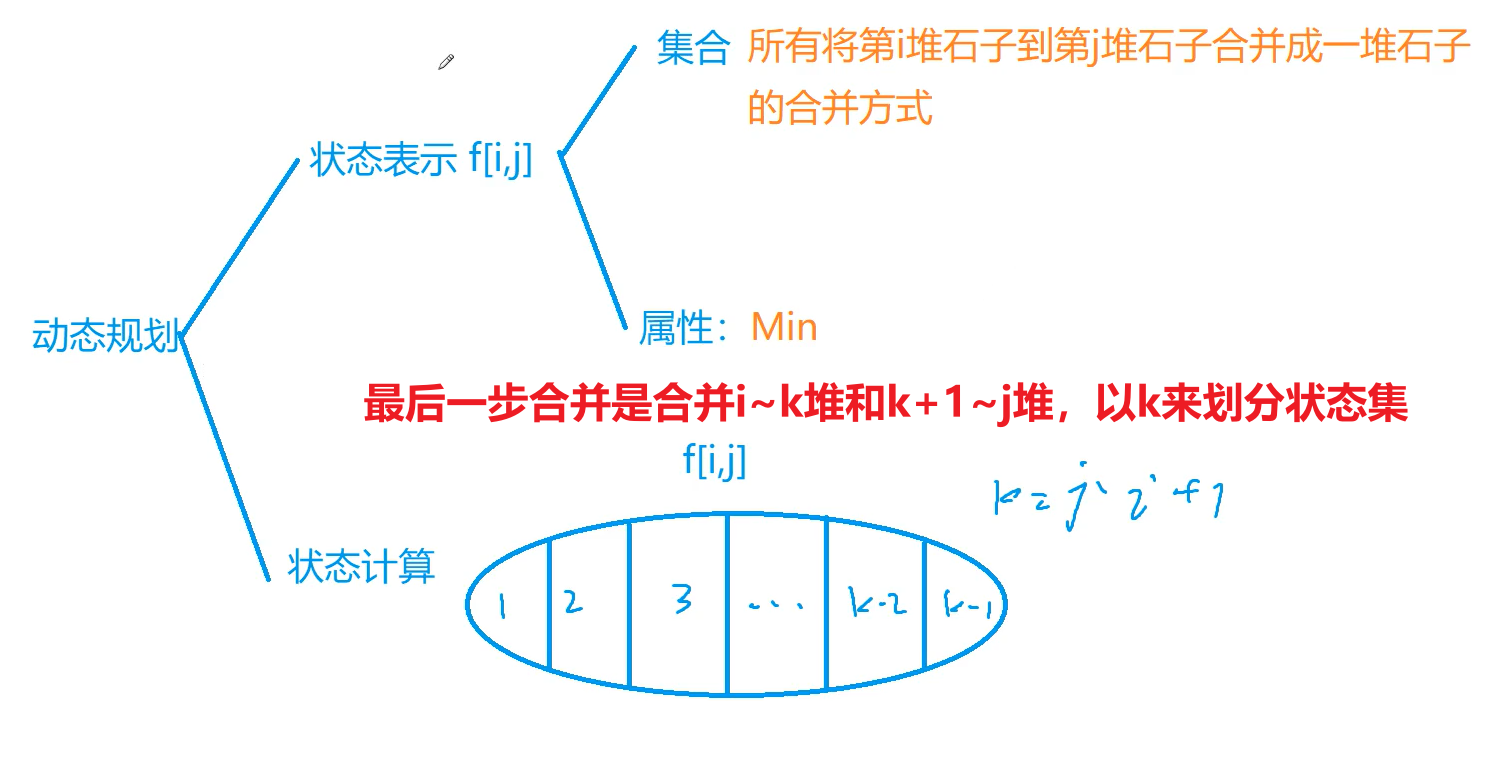
基础算法 快速排序 快速排序 分治
确定分界点 q[l],q[(l+r)/2],q[r],随机,使其值为x
调整范围 (左半边<=x)(右半边>=x),注意分界点不一定是x
递归处理左右两段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> using namespace std;const int N = 100010 ;int q[N];void quick_sort (int q[], int l, int r) if (l >= r) return ; int i = l - 1 , j = r + 1 , x = q[l + r >> 1 ]; while (i < j) { do i ++ ; while (q[i] < x); do j -- ; while (q[j] > x); if (i < j) swap (q[i], q[j]); } quick_sort (q, l, j); quick_sort (q, j + 1 , r); } int main () int n; scanf ("%d" , &n); for (int i = 0 ; i < n; i ++ ) scanf ("%d" , &q[i]); quick_sort (q, 0 , n - 1 ); for (int i = 0 ; i < n; i ++ ) printf ("%d " , q[i]); return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 def quick_sort (q, l, r ): if l >= r: return x = q[l + r >> 1 ] i = l - 1 j = r + 1 while i < j: while 1 : i += 1 if q[i] >= x: break while 1 : j -= 1 if q[j] <= x: break if i < j: q[i], q[j] = q[j], q[i] quick_sort(q, l, j) quick_sort(q, j + 1 , r) def main (): n = int (input ()) data = [int (x) for x in input ().split()] quick_sort(data, 0 , n - 1 ) print (" " .join(list (map (str , data)))) main()
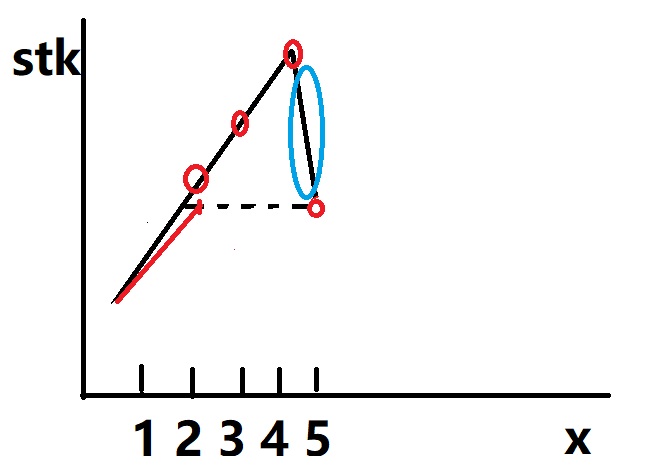
第k个数 注意这个代码左边<=x, 右边>=x, 但分界点不一定=x ,模拟一下3 4 2 8 9 5 7,这个代码可能和有些不一样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <iostream> using namespace std;const int N = 100010 ;int q[N];int quick_sort (int q[], int l, int r, int k) if (l >= r) return q[l]; int i = l - 1 , j = r + 1 , x = q[l + r >> 1 ]; while (i < j) { do i ++ ; while (q[i] < x); do j -- ; while (q[j] > x); if (i < j) swap (q[i], q[j]); } if (j - l + 1 >= k) return quick_sort (q, l, j, k); else return quick_sort (q, j + 1 , r, k - (j - l + 1 )); } int main () int n, k; scanf ("%d%d" , &n, &k); for (int i = 0 ; i < n; i ++ ) scanf ("%d" , &q[i]); cout << quick_sort (q, 0 , n - 1 , k) << endl; return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def quick_sort (q, l, r, k ): if l >= r: return q[l] x = q[l + r >> 1 ] i = l - 1 j = r + 1 while i < j: while 1 : i += 1 if q[i] >= x: break while 1 : j -= 1 if q[j] <= x: break if i < j: q[i], q[j] = q[j], q[i] if j - l + 1 >= k: return quick_sort(q, l, j, k) else : return quick_sort(q, j + 1 , r, k - (j - l + 1 )) def main (): n, k = list (map (int , input ().split())) data = [int (x) for x in input ().split()] print (quick_sort(data, 0 , n - 1 , k)) main()
归并排序 归并排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <iostream> using namespace std;const int N = 1e5 + 10 ;int a[N], tmp[N];void merge_sort (int q[], int l, int r) if (l >= r) return ; int mid = l + r >> 1 ; merge_sort (q, l, mid), merge_sort (q, mid + 1 , r); int k = 0 , i = l, j = mid + 1 ; while (i <= mid && j <= r) if (q[i] <= q[j]) tmp[k ++ ] = q[i ++ ]; else tmp[k ++ ] = q[j ++ ]; while (i <= mid) tmp[k ++ ] = q[i ++ ]; while (j <= r) tmp[k ++ ] = q[j ++ ]; for (i = l, j = 0 ; i <= r; i ++, j ++ ) q[i] = tmp[j]; } int main () int n; scanf ("%d" , &n); for (int i = 0 ; i < n; i ++ ) scanf ("%d" , &a[i]); merge_sort (a, 0 , n - 1 ); for (int i = 0 ; i < n; i ++ ) printf ("%d " , a[i]); return 0 ; }
python:python的最后收尾有更加简单的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def merge_sort (q, l, r ): if l >= r: return mid = l + r >> 1 i = l j = mid + 1 merge_sort(q, l, mid) merge_sort(q, mid + 1 , r) tmp = list () while i <= mid and j <= r: if q[i] <= q[j]: tmp.append(q[i]) i += 1 else : tmp.append(q[j]) j += 1 tmp += q[i : mid + 1 ] tmp += q[j : r + 1 ] q[l : r + 1 ] = tmp[:] def main (): n = int (input ()) data = list (map (int , input ().split())) merge_sort(data, 0 , n - 1 ) print (" " .join(list (map (str , data)))) main()
逆序对 其实在计算的过程中可以想象,只需要给后半段的每一个值计算一个逆序对数量,如果碰到q[i]>q[j],则由于前半段已经排好序,所以i~mid都是比j要大的,j位置上的逆序对数量可以计算得到,如果q[i]<=q[j],说明j位置上的逆序对需要暂缓计算(因为1~i上的值都比j小,构不成逆序对,所以j在等待一个i+k,使得q[i+k]>q[j],然后j的逆序对数量就是i+k~mid了),如果没有等到这个i+k,则说明没有逆序对值
注意边界条件>=,写错了可就EML
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <iostream> using namespace std;typedef long long LL;const int N = 1e5 + 10 ;int a[N], tmp[N];LL merge_sort (int q[], int l, int r) if (l >= r) return 0 ; int mid = l + r >> 1 ; LL res = merge_sort (q, l, mid) + merge_sort (q, mid + 1 , r); int k = 0 , i = l, j = mid + 1 ; while (i <= mid && j <= r) if (q[i] <= q[j]) tmp[k ++ ] = q[i ++ ]; else { res += mid - i + 1 ; tmp[k ++ ] = q[j ++ ]; } while (i <= mid) tmp[k ++ ] = q[i ++ ]; while (j <= r) tmp[k ++ ] = q[j ++ ]; for (i = l, j = 0 ; i <= r; i ++, j ++ ) q[i] = tmp[j]; return res; } int main () int n; scanf ("%d" , &n); for (int i = 0 ; i < n; i ++ ) scanf ("%d" , &a[i]); cout << merge_sort (a, 0 , n - 1 ) << endl; return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def merge_sort (q, l, r ): if l >= r: return 0 mid = l + r >> 1 i = l j = mid + 1 result = merge_sort(q, l, mid) + merge_sort(q, mid + 1 , r) tmp = list () while i <= mid and j <= r: if q[i] <= q[j]: tmp.append(q[i]) i += 1 else : tmp.append(q[j]) j += 1 result = result + mid - i + 1 tmp += q[i : mid + 1 ] tmp += q[j : r + 1 ] q[l : r + 1 ] = tmp[:] return result def main (): n = int (input ()) data = list (map (int , input ().split())) print (merge_sort(data, 0 , n - 1 )) main()
二分 数的范围 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <iostream> using namespace std;const int N = 100010 ;int n, m;int q[N];int main () scanf ("%d%d" , &n, &m); for (int i = 0 ; i < n; i ++ ) scanf ("%d" , &q[i]); while (m -- ) { int x; scanf ("%d" , &x); int l = 0 , r = n - 1 ; while (l < r) { int mid = l + r >> 1 ; if (q[mid] >= x) r = mid; else l = mid + 1 ; } if (q[l] != x) cout << "-1 -1" << endl; else { cout << l << ' ' ; int l = 0 , r = n - 1 ; while (l < r) { int mid = l + r + 1 >> 1 ; if (q[mid] <= x) l = mid; else r = mid - 1 ; } cout << l << endl; } } return 0 ; }
python:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def binary_search (q, n, k ): l, r = 0 , n - 1 while l < r: mid = l + r >> 1 if q[mid] >= k: r = mid else : l = mid + 1 if q[l] != k: print ("-1 -1" ) else : print (l, end=" " ) l, r = 0 , n - 1 while l < r: mid = l + r + 1 >> 1 if q[mid] <= k: l = mid else : r = mid - 1 print (l) def main (): n, m = list (map (int , input ().split())) data = list (map (int , input ().split())) for i in range (m): k = int (input ()) binary_search(data, n, k) main()
整数二分总结 整数二分法:有单调性可以二分,无单调性也可能可以。主要是否存在一种性质能把区间分成两半——边界
二分可以求这个划分的边界,存在左半部分的右边界和右半部分的左边界,有两套模板,选择的时候判断性质把mid放在left还是right上
二分每次都覆盖最终的结果,最后只剩一个数的时候就是结果
二分模板一共有两个,分别适用于不同情况。
版本1
1 2 3 4 5 6 7 8 9 10 int bsearch_1 (int l, int r) while (l < r) { int mid = l + r >> 1 ; if (check (mid)) r = mid; else l = mid + 1 ; } return l; }
版本2
1 2 3 4 5 6 7 8 9 10 int bsearch_2 (int l, int r) while (l < r) { int mid = l + r + 1 >> 1 ; if (check (mid)) l = mid; else r = mid - 1 ; } return l; }
假设有一个总区间,经由我们的 check 函数判断后,可分成两部分,
如果我们的目标是下面这个v,那麽就必须使用模板 1
…………….vooooooooo
假设经由 check 划分后,整个区间的属性与目标v如下,则我们必须使用模板 2
oooooooov……………….
所以下次可以观察 check 属性再与模板1 or 2 互相搭配就不会写错啦
数的三次方根 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <iostream> using namespace std;int main () double x; cin >> x; double l = -100 , r = 100 ; while (r - l > 1e-8 ) { double mid = (l + r) / 2 ; if (mid * mid * mid >= x) r = mid; else l = mid; } printf ("%.6lf\n" , l); return 0 ; }
(c语言printf()输出格式大全_printf输出格式_rusty_knife的博客-CSDN博客
double输出为%lf
python
python print()函数控制输出格式_python 打印格式格式-CSDN博客
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def binary_search (x ): l = -10000 r = 10000 while r - l >= 1e-8 : mid = (l+r)/2.0 if mid**3 >= x: r = mid else : l = mid return l def main (): x = float (input ()) result = binary_search(x) print ("{:.6f}" .format (result)) main()
浮点二分总结 浮点二分是类似于整数二分的,且其无需考虑+1-1的,需要注意:
while的条件,r-l>精度*10^-2^,比如题目要求精度是-6次,r-l>1e-8
r和l直接取边界值即可
高精度
tips:
注意处理进位,包括最高位的进位
借位的处理,借位不是t/10,而是正负判定赋值
注意是否需要处理前导0,注意乘法是不是可以乘以0
string的存储:”12345”
高精度加法
存储时使用数组存储(可用vector),从个位开始存储,如数12345,在数组里的存储方式为:(为了方便加法)
数组的第X位
0
1
2
3
4
存储的数字
5
4
3
2
1
运算的方法:模拟人工加法,每一位的结果等于两个数该位的结果加上低位的进位
不压位代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <iostream> #include <vector> using namespace std;vector<int > add (vector<int > &A, vector<int > &B) if (A.size () < B.size ()) return add (B, A); vector<int > C; int t = 0 ; for (int i = 0 ; i < A.size (); i ++ ) { t += A[i]; if (i < B.size ()) t += B[i]; C.push_back (t % 10 ); t /= 10 ; } if (t) C.push_back (t); return C; } int main () string a, b; vector<int > A, B; cin >> a >> b; for (int i = a.size () - 1 ; i >= 0 ; i -- ) A.push_back (a[i] - '0' ); for (int i = b.size () - 1 ; i >= 0 ; i -- ) B.push_back (b[i] - '0' ); auto C = add (A, B); for (int i = C.size () - 1 ; i >= 0 ; i -- ) cout << C[i]; cout << endl; return 0 ; }
压位代码
压位能减小所需空间,高精度加法可以压9位,乘法可以压4位,压9位就是数组的一位表示原数的9位(int范围的限制)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 #include <iostream> #include <vector> using namespace std;const int base = 1000000000 ;vector<int > add (vector<int > &A, vector<int > &B) if (A.size () < B.size ()) return add (B, A); vector<int > C; int t = 0 ; for (int i = 0 ; i < A.size (); i ++ ) { t += A[i]; if (i < B.size ()) t += B[i]; C.push_back (t % base); t /= base; } if (t) C.push_back (t); return C; } int main () string a, b; vector<int > A, B; cin >> a >> b; for (int i = a.size () - 1 , s = 0 , j = 0 , t = 1 ; i >= 0 ; i -- ) { s += (a[i] - '0' ) * t; j ++, t *= 10 ; if (j == 9 || i == 0 ) { A.push_back (s); s = j = 0 ; t = 1 ; } } for (int i = b.size () - 1 , s = 0 , j = 0 , t = 1 ; i >= 0 ; i -- ) { s += (b[i] - '0' ) * t; j ++, t *= 10 ; if (j == 9 || i == 0 ) { B.push_back (s); s = j = 0 ; t = 1 ; } } auto C = add (A, B); cout << C.back (); for (int i = C.size () - 2 ; i >= 0 ; i -- ) printf ("%09d" , C[i]); cout << endl; return 0 ; }
虽然python自带大整数计算,但是还是模拟一下算法思想:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def add (A,B ): if len (A)<len (B): return add(B,A) t = 0 result = [] for i in range (len (A)): t += A[i] if i < len (B): t += B[i] result.append(t%10 ) t = t // 10 if t : result.append(t) return result def main (): A = list (map (int ,list (input ()))) B = list (map (int ,list (input ()))) A.reverse() B.reverse() C = add(A,B) C.reverse() print ('' .join(list (map (str ,C)))) main()
高精度减法
需要首先保证sub(A,B)中有A>=B
然后逐位作差,注意借位
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <iostream> #include <vector> using namespace std;bool cmp (vector<int > &A, vector<int > &B) if (A.size () != B.size ()) return A.size () > B.size (); for (int i = A.size () - 1 ; i >= 0 ; i -- ) if (A[i] != B[i]) return A[i] > B[i]; return true ; } vector<int > sub (vector<int > &A, vector<int > &B) vector<int > C; for (int i = 0 , t = 0 ; i < A.size (); i ++ ) { t = A[i] - t; if (i < B.size ()) t -= B[i]; C.push_back ((t + 10 ) % 10 ); if (t < 0 ) t = 1 ; else t = 0 ; } while (C.size () > 1 && C.back () == 0 ) C.pop_back (); return C; } int main () string a, b; vector<int > A, B; cin >> a >> b; for (int i = a.size () - 1 ; i >= 0 ; i -- ) A.push_back (a[i] - '0' ); for (int i = b.size () - 1 ; i >= 0 ; i -- ) B.push_back (b[i] - '0' ); vector<int > C; if (cmp (A, B)) C = sub (A, B); else C = sub (B, A), cout << '-' ; for (int i = C.size () - 1 ; i >= 0 ; i -- ) cout << C[i]; cout << endl; return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 def cmp (A, B ): if len (A) != len (B): return len (A) > len (B) for i in range (len (A) - 1 , -1 , -1 ): if A[i] != B[i]: return A[i] > B[i] return True def sub (A, B ): t = 0 result = [] for i in range (len (A)): t = A[i] - t if i < len (B): t -= B[i] result.append((t + 10 ) % 10 ) if t < 0 : t = 1 else : t = 0 while len (result) > 1 and result[-1 ] == 0 : result.pop() return result def main (): A = list (map (int , input ())) B = list (map (int , input ())) A.reverse() B.reverse() if cmp(A, B): C = sub(A, B) else : print ("-" , end="" ) C = sub(B, A) C.reverse() print ("" .join(map (str , C))) main()
高精度乘法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <iostream> #include <vector> using namespace std;vector<int > mul (vector<int > &A, int b) vector<int > C; int t = 0 ; for (int i = 0 ; i < A.size () || t; i ++ ) { if (i < A.size ()) t += A[i] * b; C.push_back (t % 10 ); t /= 10 ; } while (C.size () > 1 && C.back () == 0 ) C.pop_back (); return C; } int main () string a; int b; cin >> a >> b; vector<int > A; for (int i = a.size () - 1 ; i >= 0 ; i -- ) A.push_back (a[i] - '0' ); auto C = mul (A, b); for (int i = C.size () - 1 ; i >= 0 ; i -- ) printf ("%d" , C[i]); return 0 ; }
上面这种方法不太好记忆,也可以采用下面这种:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> #include <vector> #include <cstring> using namespace std;vector<int > dot (vector<int >&A,int b) int t=0 ; vector<int > res; for (int i=0 ;i<A.size ();i++) { t+=A[i]*b; res.push_back (t%10 ); t=t/10 ; } while (t) { res.push_back (t%10 ); t=t/10 ; } while (res.back ()==0 &&res.size ()>1 ) res.pop_back (); return res; } int main () string a; int b; cin>>a>>b; vector<int >A,C; for (int i=a.size ()-1 ;i>=0 ;i--) A.push_back (a[i]-'0' ); C=dot (A,b); for (int i=C.size ()-1 ;i>=0 ;i--) cout<<C[i]; return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def mul (A, b ): t = 0 result = [] for i in range (len (A)): t += A[i] * b result.append(t % 10 ) t = t // 10 while t: result.append(t % 10 ) t = t // 10 while len (result) > 1 and result[-1 ] == 0 : result.pop() return result def main (): A = list (map (int , input ())) b = int (input ()) A.reverse() C = mul(A, b) C.reverse() print ("" .join(map (str , C))) main()
高精度除法
类似于人做除法,从高位开始除,注意对余数的处理
除完后得到的是从0开始高位——低位的格式,进行反转
处理前导0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <iostream> #include <vector> #include <algorithm> using namespace std;vector<int > div (vector<int > &A, int b, int &r) vector<int > C; r = 0 ; for (int i = A.size () - 1 ; i >= 0 ; i -- ) { r = r * 10 + A[i]; C.push_back (r / b); r %= b; } reverse (C.begin (), C.end ()); while (C.size () > 1 && C.back () == 0 ) C.pop_back (); return C; } int main () string a; vector<int > A; int B; cin >> a >> B; for (int i = a.size () - 1 ; i >= 0 ; i -- ) A.push_back (a[i] - '0' ); int r; auto C = div (A, B, r); for (int i = C.size () - 1 ; i >= 0 ; i -- ) cout << C[i]; cout << endl << r << endl; return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def div (A, B ): r = 0 result = [] for i in range (len (A) - 1 , -1 , -1 ): r = r * 10 + A[i] result.append(r // B) r %= B result.reverse() while len (result) > 1 and result[-1 ] == 0 : result.pop() return result, r def main (): A = list (map (int , input ())) B = int (input ()) C, r = div(A, B) C.reverse() print ("" .join(map (str , C))) print (r) main()
前缀和和差分 一维前缀和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include < iostream> using namespace std;const int N = 100010 ;int n, m;int a[N], s[N];int main () scanf ("%d%d" , &n, &m); for (int i = 1 ; i <= n; i ++ ) scanf ("%d" , &a[i]); for (int i = 1 ; i <= n; i ++ ) s[i] = s[i - 1 ] + a[i]; while (m -- ) { int l, r; scanf ("%d%d" , &l, &r); printf ("%d\n" , s[r] - s[l - 1 ]); } return 0 ; }
如果不需要原来的数组,也可以直接用a数组自己来变换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> using namespace std;const int N=100010 ;int n,m;int a[N];int main () cin>>n>>m; for (int i=1 ;i<=n;i++) { cin>>a[i]; } for (int i=1 ;i<=n;i++) { a[i]=a[i]+a[i-1 ]; } int st,ed; for (int i=1 ;i<=m;i++) { cin>>st>>ed; cout<<a[ed]-a[st-1 ]<<endl; } return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 N = 100010 a = [0 ]*N s = [0 ]*N def main (): n,m = map (int ,input ().split()) a[1 :n+1 ] = list (map (int ,input ().split())) for i in range (1 ,n+1 ): s[i] = s[i-1 ] + a[i] for i in range (m): l,r = map (int ,input ().split()) print (s[r]-s[l-1 ]) main()
二维前缀和
$S[i][j]$存储包括$a[i][j]$的左上侧元素的和
$S[i][j]=S[i-1][j]+S[i][j-1]-S[i-1][j-1]+a[i][j]$
查询$(x_1,y_1)$和$(x_2,y_2)$范围内元素的和(包括这两个点),$S[x_2][y_2]-S[x_2][y_1-1]-S[x_1-1][y_2]+S[x_1-1][y_1-1]$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <iostream> using namespace std;const int N = 1010 ;int n, m, q;int s[N][N];int main () scanf ("%d%d%d" , &n, &m, &q); for (int i = 1 ; i <= n; i ++ ) for (int j = 1 ; j <= m; j ++ ) scanf ("%d" , &s[i][j]); for (int i = 1 ; i <= n; i ++ ) for (int j = 1 ; j <= m; j ++ ) s[i][j] += s[i - 1 ][j] + s[i][j - 1 ] - s[i - 1 ][j - 1 ]; while (q -- ) { int x1, y1, x2, y2; scanf ("%d%d%d%d" , &x1, &y1, &x2, &y2); printf ("%d\n" , s[x2][y2] - s[x1 - 1 ][y2] - s[x2][y1 - 1 ] + s[x1 - 1 ][y1 - 1 ]); } return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 N = 1010 a = [[0 ] * N for _ in range (N)] s = [[0 ] * N for _ in range (N)] def main (): n, m, q = map (int , input ().split()) for i in range (1 , n + 1 ): a[i][1 : m + 1 ] = list (map (int , input ().split())) for i in range (1 , n + 1 ): for j in range (1 , m + 1 ): s[i][j] = s[i - 1 ][j] + s[i][j - 1 ] - s[i - 1 ][j - 1 ] + a[i][j] for i in range (q): x1, y1, x2, y2 = map (int , input ().split()) print (s[x2][y2] - s[x2][y1 - 1 ] - s[x1 - 1 ][y2] + s[x1 - 1 ][y1 - 1 ]) main()
一维差分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <iostream> using namespace std;const int N = 100010 ;int n, m;int a[N], b[N];void insert (int l, int r, int c) b[l] += c; b[r + 1 ] -= c; } int main () scanf ("%d%d" , &n, &m); for (int i = 1 ; i <= n; i ++ ) scanf ("%d" , &a[i]); for (int i = 1 ; i <= n; i ++ ) insert (i, i, a[i]); while (m -- ) { int l, r, c; scanf ("%d%d%d" , &l, &r, &c); insert (l, r, c); } for (int i = 1 ; i <= n; i ++ ) b[i] += b[i - 1 ]; for (int i = 1 ; i <= n; i ++ ) printf ("%d " , b[i]); return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 N = 100010 a = [0 ] * N b = [0 ] * N def insert (l, r, c ): b[l] += c b[r + 1 ] -= c def main (): n, m = map (int , input ().split()) a[1 : n + 1 ] = list (map (int , input ().split())) for i in range (1 , n + 1 ): insert(i, i, a[i]) for i in range (m): l, r, c = map (int , input ().split()) insert(l, r, c) for i in range (1 , n + 1 ): b[i] = b[i] + b[i - 1 ] print (" " .join(map (str , b[1 : n + 1 ]))) main()
二维差分
核心思想:给定原矩阵a[i,j],构造差分矩阵b[i,j],使得a是b的前缀和
核心操作:给以(x1,y1)为左上角,(x2,y2)为右下角的子矩阵中的所有数加上c,其对于差分矩阵的影响是
S[x1,y1]+=c;S[x1,y2+1]-=c;S[x2+1,y1]-=c;S[x2+1,y2+1]+=c同样不需要显式构造差分矩阵,借助核心操作可完成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <iostream> using namespace std;const int N = 1010 ;int n, m, q;int a[N][N], b[N][N];void insert (int x1, int y1, int x2, int y2, int c) b[x1][y1] += c; b[x2 + 1 ][y1] -= c; b[x1][y2 + 1 ] -= c; b[x2 + 1 ][y2 + 1 ] += c; } int main () scanf ("%d%d%d" , &n, &m, &q); for (int i = 1 ; i <= n; i ++ ) for (int j = 1 ; j <= m; j ++ ) scanf ("%d" , &a[i][j]); for (int i = 1 ; i <= n; i ++ ) for (int j = 1 ; j <= m; j ++ ) insert (i, j, i, j, a[i][j]); while (q -- ) { int x1, y1, x2, y2, c; cin >> x1 >> y1 >> x2 >> y2 >> c; insert (x1, y1, x2, y2, c); } for (int i = 1 ; i <= n; i ++ ) for (int j = 1 ; j <= m; j ++ ) b[i][j] += b[i - 1 ][j] + b[i][j - 1 ] - b[i - 1 ][j - 1 ]; for (int i = 1 ; i <= n; i ++ ) { for (int j = 1 ; j <= m; j ++ ) printf ("%d " , b[i][j]); puts ("" ); } return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 N = 1010 a = [[0 ] * N for _ in range (N)] b = [[0 ] * N for _ in range (N)] def insert (x1, y1, x2, y2, c ): b[x1][y1] += c b[x1][y2 + 1 ] -= c b[x2 + 1 ][y1] -= c b[x2 + 1 ][y2 + 1 ] += c def main (): n, m, q = map (int , input ().split()) for i in range (1 , n + 1 ): a[i][1 : m + 1 ] = list (map (int , input ().split())) for i in range (1 , n + 1 ): for j in range (1 , m + 1 ): insert(i, j, i, j, a[i][j]) for i in range (q): x1, y1, x2, y2, c = map (int , input ().split()) insert(x1, y1, x2, y2, c) for i in range (1 , n + 1 ): for j in range (1 , m + 1 ): b[i][j] += b[i - 1 ][j] + b[i][j - 1 ] - b[i - 1 ][j - 1 ] for i in range (1 , n + 1 ): print (" " .join(map (str , b[i][1 : m + 1 ]))) main()
双指针算法
归并排序双指针指向两个数组,快排双指针指向一个数组
核心思想:将朴素的二重循环优化到$O(n)$
写的时候首先写朴素的二重循环(先枚举终点,再枚举起点),然后考虑i,j之间的关系,是否存在单调的关系
!!!模板:
1 2 3 4 5 for (int i=0 ,j=0 ;i<n;i++){ while (j<i&&check (i,j)) j++; }
最长连续不重复子序列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> using namespace std;const int N = 100010 ;int n;int q[N], s[N];int main () scanf ("%d" , &n); for (int i = 0 ; i < n; i ++ ) scanf ("%d" , &q[i]); int res = 0 ; for (int i = 0 , j = 0 ; i < n; i ++ ) { s[q[i]] ++ ; while (j < i && s[q[i]] > 1 ) s[q[j ++ ]] -- ; res = max (res, i - j + 1 ); } cout << res << endl; return 0 ; }
python :直接开数组的写法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 N = 100010 s = [0 ]*N def main (): n = int (input ()) data = list (map (int ,input ().split())) res = 0 j = 0 for i in range (n): s[data[i]] += 1 while j<i and s[data[i]] > 1 : s[data[j]] -= 1 j += 1 res = max (res, i-j+1 ) print (res) main()
python:采用内置字典的写法
dict.fromkeys([],0) 初始化dict
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def main (): n = int (input ()) data = list (map (int ,input ().split())) d = dict .fromkeys(data,0 ) j = 0 res = 0 for i in range (n): d[data[i]] += 1 while d[data[i]]>1 and j<i: d[data[j]] -= 1 j += 1 res = max (res,i-j+1 ) print (res) main()
数组元素的目标和 考虑单调性去优化二重朴素循环
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <iostream> using namespace std;const int N=100010 ;int n,m,x;int a[N];int b[N];int main () scanf ("%d%d%d" ,&n,&m,&x); for (int i=0 ;i<n;i++) scanf ("%d" ,&a[i]); for (int j=0 ;j<m;j++) scanf ("%d" ,&b[j]); for (int i=n-1 ,j=0 ;i>=0 ;i--) { while (j<m&&a[i]+b[j]<x) j++; if (a[i]+b[j]==x) { cout<<i<<" " <<j; break ; } } return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 def main (): n, m, x = map (int , input ().split()) a = list (map (int , input ().split())) b = list (map (int , input ().split())) j = m - 1 for i in range (n): while a[i] + b[j] > x and j > 0 : j -= 1 if a[i] + b[j] == x: print (i, j) break main()
判断子序列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #include <iostream> #include <cstring> using namespace std;const int N = 100010 ;int n, m;int a[N], b[N];int main () scanf ("%d%d" , &n, &m); for (int i = 0 ; i < n; i ++ ) scanf ("%d" , &a[i]); for (int i = 0 ; i < m; i ++ ) scanf ("%d" , &b[i]); int i = 0 , j = 0 ; while (i < n && j < m) { if (a[i] == b[j]) i ++ ; j ++ ; } if (i == n) puts ("Yes" ); else puts ("No" ); return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def main (): n, m = map (int , input ().split()) a = list (map (int , input ().split())) b = list (map (int , input ().split())) i, j = 0 , 0 while i < n and j < m: if a[i] == b[j]: i += 1 j += 1 if i == n: print ("Yes" ) else : print ("No" ) main()
位运算 求n的第k位数字:n>>k&1
返回n的最后一位:lowbit(n)=n&-n,如:
x=1010,lowbit(x)=10
x=101000,lowbit(x)=1000
二进制中1的个数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <iostream> using namespace std;int main () int n; scanf ("%d" , &n); while (n -- ) { int x, s = 0 ; scanf ("%d" , &x); for (int i = x; i; i -= i & -i) s ++ ; printf ("%d " , s); } return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 def main (): n = int (input ()) data = list (map (int ,input ().split())) for x in data: res = 0 while x: x = x - (x&-x) res += 1 print (res,end=' ' ) main()
离散化 当值域跨度大,但点分布比较稀疏时可用离散化,如给定数-1e10,-1,1e10,该数上所在位置对应一个数,此时可用一个数组中存储上述列举的稀疏的数,一个数组来存储对应的数
离散化的本质是建立了一段数列到自然数之间的映射关系(value -> index),通过建立新索引,来缩小目标区间,使得可以进行一系列连续数组可以进行的操作比如二分,前缀和等…
离散化首先需要排序去重:
1 2 3 4 1. 排序:sort (alls.begin (),alls.end ())2. 去重:alls.earse (unique (alls.begin (),alls.end ()),alls.end ());unique (alls.begin (),alls.end ())
unique()函数的底层原理
1 2 3 4 5 6 7 8 vector<int >::iterator unique (vector<int > &a) { int j = 0 ; for (int i = 0 ; i < a.size (); ++i) { if (!i || a[i] != a[i - 1 ]) a[j++] = a[i]; } return a.begin () + j; }
区间和 建立x->value的映射,但是又不能是数组那种直接hash,所以做法是把所有可能的下标都记录下来,去重后,然后再建立一个新的数组来存放固定好x后的他们的value值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 #include <iostream> #include <vector> #include <algorithm> using namespace std;typedef pair<int , int > PII;const int N = 300010 ;int n, m;int a[N], s[N];vector<int > alls; vector<PII> add, query; int find (int x) int l = 0 , r = alls.size () - 1 ; while (l < r) { int mid = l + r >> 1 ; if (alls[mid] >= x) r = mid; else l = mid + 1 ; } return r + 1 ; } int main () cin >> n >> m; for (int i = 0 ; i < n; i ++ ) { int x, c; cin >> x >> c; add.push_back ({x, c}); alls.push_back (x); } for (int i = 0 ; i < m; i ++ ) { int l, r; cin >> l >> r; query.push_back ({l, r}); alls.push_back (l); alls.push_back (r); } sort (alls.begin (), alls.end ()); alls.erase (unique (alls.begin (), alls.end ()), alls.end ()); for (auto item : add) { int x = find (item.first); a[x] += item.second; } for (int i = 1 ; i <= alls.size (); i ++ ) s[i] = s[i - 1 ] + a[i]; for (auto item : query) { int l = find (item.first), r = find (item.second); cout << s[r] - s[l - 1 ] << endl; } return 0 ; }
python:因为把query的下标都加入了,所以这里的find函数一定能找到相同值,如果不插入的话,就需要写两个find函数分别查找大于等于l的下标和小于等于r的下标了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def find (k, num ): l = 0 r = len (k) - 1 while l < r: mid = l + r >> 1 if k[mid] >= num: r = mid else : l = mid + 1 return l + 1 def main (): n, m = map (int , input ().split()) add = [list (map (int , input ().split())) for _ in range (n)] query = [list (map (int , input ().split())) for _ in range (m)] d = dict () for item in add: d[item[0 ]] = d.get(item[0 ], 0 ) + item[1 ] for item in query: d[item[0 ]] = d.get(item[0 ], 0 ) d[item[1 ]] = d.get(item[1 ], 0 ) d = sorted (d.items()) k = [i[0 ] for i in d] v = [0 ] + [i[1 ] for i in d] for i in range (1 , len (v)): v[i] = v[i - 1 ] + v[i] for pair in query: l = find(k, pair[0 ]) r = find(k, pair[1 ]) print (v[r] - v[l - 1 ]) main()
区间合并 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <iostream> #include <vector> #include <algorithm> using namespace std;typedef pair<int ,int >PII;int n;void merge (vector<PII>&segs) vector<PII> res; sort (segs.begin (),segs.end ()); int st=-2e9 ,ed=-2e9 ; for (auto item:segs) { if (item.first>ed) { if (st!=-2e9 ) res.push_back ({st,ed}); st=item.first,ed=item.second; } else ed=max (ed,item.second); } if (st!=-2e9 ) res.push_back ({st,ed}); segs=res; } int main () cin>>n; int l,r; vector<PII>segs; for (int i=0 ;i<n;i++) { cin>>l>>r; segs.push_back ({l,r}); } merge (segs); cout<<segs.size (); return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def merge (data ): data.sort(key=lambda x: x[0 ]) st, ed = -2e9 , -2e9 res = [] for item in data: if item[0 ] > ed: if st != -2e9 : res.append([st, ed]) st, ed = item else : ed = max (ed, item[1 ]) if st != -2e9 : res.append([st, ed]) return res def main (): n = int (input ()) data = [list (map (int , input ().split())) for _ in range (n)] data = merge(data) print (len (data)) main()
数据结构 单链表 一般单链表的实现:指针+结构体
1 2 3 4 struct Node { int val; Node* next; };
但在笔试题里面不怎么用,因为new的时候耗时比较高,在面试中常用
单链表,用得最多的是邻接表(n个链表),可用于存储树和图
双链表,用于优化某些问题
1 2 int head,idx,e[N],ne[N];
下面是单链表的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 #include <iostream> using namespace std;const int N = 100010 ;int head, e[N], ne[N], idx;void init () head = -1 ; idx = 0 ; } void add_to_head (int x) e[idx] = x, ne[idx] = head, head = idx ++ ; } void add (int k, int x) e[idx] = x, ne[idx] = ne[k], ne[k] = idx ++ ; } void remove (int k) ne[k] = ne[ne[k]]; } int main () int m; cin >> m; init (); while (m -- ) { int k, x; char op; cin >> op; if (op == 'H' ) { cin >> x; add_to_head (x); } else if (op == 'D' ) { cin >> k; if (!k) head = ne[head]; else remove (k - 1 ); } else { cin >> k >> x; add (k - 1 , x); } } for (int i = head; i != -1 ; i = ne[i]) cout << e[i] << ' ' ; cout << endl; return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 N = 100010 e = [0 ]*N ne = [0 ]*N head,idx = -1 ,0 def add_to_head (x ): global idx,head e[idx]=x ne[idx]=head head = idx idx +=1 def add (k,x ): global idx e[idx] = x ne[idx] = ne[k] ne[k]=idx idx += 1 def remove (k ): ne[k]=ne[ne[k]] def main (): global idx,head m = int (input ()) for i in range (m): op = input ().split() if op[0 ]=='H' : x = int (op[1 ]) add_to_head(x) elif op[0 ]=='D' : k = int (op[1 ]) if k==0 : head = ne[head] else : remove(k-1 ) else : k,x = int (op[1 ]),int (op[2 ]) add(k-1 ,x) i = head while i!=-1 : print (e[i],end = ' ' ) i = ne[i] main()
双链表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 #include <iostream> using namespace std;const int N=100010 ;int e[N],l[N],r[N],idx,m;void init () r[0 ]=1 ; l[1 ]=0 ; idx=2 ; } void insert (int k,int x) e[idx]=x; l[idx]=k; r[idx]=r[k]; l[r[k]]=idx; r[k]=idx; idx++; } void remove (int k) l[r[k]]=l[k]; r[l[k]]=r[k]; } int main () cin>>m; init (); while (m--) { string op; int x,k; cin>>op; if (op=="L" ) { cin>>x; insert (0 ,x); } else if (op=="R" ) { cin>>x; insert (l[1 ],x); } else if (op=="D" ) { cin>>k; remove (k+1 ); } else if (op=="IL" ) { cin>>k>>x; insert (l[k+1 ],x); }else { cin>>k>>x; insert (k+1 ,x); } } for (int i=r[0 ];i!=1 ;i=r[i]) { cout<<e[i]<<" " ; } return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 N = 100010 e = [0 ] * N l = [0 ] * N r = [0 ] * N idx = 2 def init (): r[0 ] = 1 l[1 ] = 0 def insert (k, x ): global idx e[idx] = x l[r[k]] = idx r[idx] = r[k] l[idx] = k r[k] = idx idx += 1 def remove (k ): l[r[k]] = l[k] r[l[k]] = r[k] def main (): global idx init() m = int (input ()) for i in range (m): op = input ().split() if op[0 ] == "L" : x = int (op[1 ]) insert(0 , x) elif op[0 ] == "R" : x = int (op[1 ]) insert(l[1 ], x) elif op[0 ] == "D" : k = int (op[1 ]) remove(k + 1 ) elif op[0 ] == "IL" : k, x = int (op[1 ]), int (op[2 ]) insert(l[k + 1 ], x) else : k, x = int (op[1 ]), int (op[2 ]) insert(k + 1 , x) i = r[0 ] while i != 1 : print (e[i], end=" " ) i = r[i] main()
栈 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> using namespace std;const int N=100010 ;int stk[N],tt;stk[++tt]=x; tt--; if (tt>0 ) not emptyelse emptystk[tt];
模拟栈 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> using namespace std;const int N=100010 ;int m;int stk[N],tt;int main () cin>>m; while (m--) { string op; int x; cin>>op; if (op=="push" ) { cin>>x; stk[++tt]=x; }else if (op=="pop" ) { tt--; }else if (op=="empty" ) { cout<<(tt?"NO" :"YES" )<<endl; }else { cout<<stk[tt]<<endl; } } return 0 ; }
python:借助python特性简化一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def main (): m = int (input ()) stk = [] for i in range (m): op = input ().split() if op[0 ] == 'push' : x = int (op[1 ]) stk.append(x) elif op[0 ] == 'pop' : stk.pop() elif op[0 ] == 'empty' : print ('NO' if len (stk) else 'YES' ) else : print (stk[-1 ]) main()
表达式求值 如果所有字符的运算顺序都相同,也就是说从左往右算和从右往左算都无区别,那我们可以将所有数字压进栈中,所有操作符压进栈中,然后做eval操作,但是并不是所有情况我们都可以从后往前直接算的
如果前面运算符的优先级高的话或者相等(运算符优先级相等的话从左往右算),我们必须先算前面的操作,如3*5-2,就不能先算5-2
如果前面有括号,就必须先算括号里的,如(3-2)*5,就不能先算2*5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <iostream> #include <stack> #include <unordered_map> #include <cstring> #include <algorithm> using namespace std;stack<int >num; stack<char >op; void eval () auto b=num.top ();num.pop (); auto a=num.top ();num.pop (); auto c=op.top ();op.pop (); int x; if (c=='+' ) x=a+b; else if (c=='-' ) x=a-b; else if (c=='*' ) x=a*b; else x=a/b; num.push (x); } int main () unordered_map<char ,int > pr{{'+' ,1 },{'-' ,1 },{'*' ,2 },{'/' ,2 }}; string str; cin>>str; for (int i=0 ;i<str.size ();i++) { auto c=str[i]; if (isdigit (c)) { int x=0 ,j=i; while (j<str.size ()&&isdigit (str[j])) x=x*10 +str[j++]-'0' ; i=j-1 ; num.push (x); } else if (c=='(' ) op.push (c); else if (c==')' ) { while (op.top ()!='(' ) eval (); op.pop (); } else { while (op.size ()&&op.top ()!='(' &&pr[op.top ()]>=pr[c]) eval (); op.push (c); } } while (op.size ()) eval (); cout<<num.top ()<<endl; return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 pr = {"+" : 1 , "-" : 1 , "*" : 2 , "/" : 2 } num = [] op = [] def myeval (): b = num.pop() a = num.pop() c = op.pop() x = 0 if c == "+" : x = a + b elif c == "-" : x = a - b elif c == "*" : x = a * b else : x = int (a / b) num.append(x) def main (): exp = input () i = 0 while i < len (exp): if exp[i].isdigit(): j = i while j < len (exp) and exp[j].isdigit(): j += 1 num.append(int (exp[i:j])) i = j - 1 elif exp[i] == "(" : op.append(exp[i]) elif exp[i] == ")" : while op[-1 ] != "(" : myeval() op.pop() else : while len (op) and op[-1 ] != "(" and pr[op[-1 ]] >= pr[exp[i]]: myeval() op.append(exp[i]) i += 1 while len (op): myeval() print (num[-1 ]) main()
队列 栈和队列书写思路对比:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <iostream> using namespace std;const int N=100010 ;int stk[N],tt;stk[++tt]=x; tt--; if (tt>0 ) not emptyelse emptystk[tt]; int q[N],hh,tt=-1 ;q[++tt]=x; hh++; if (hh<=tt) not emptyelse emptyq[hh] q[tt]
模拟队列操作代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <iostream> using namespace std;const int N = 100010 ;int m;int q[N], hh, tt = -1 ;int main () cin >> m; while (m -- ) { string op; int x; cin >> op; if (op == "push" ) { cin >> x; q[ ++ tt] = x; } else if (op == "pop" ) hh ++ ; else if (op == "empty" ) cout << (hh <= tt ? "NO" : "YES" ) << endl; else cout << q[hh] << endl; } return 0 ; }
python版本
写法1:时间复杂度比较高,因为append(op[1])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 q = [] def main (): num = int (input ()) for i in range (num): op = input ().split() ch = op[0 ] if ch == 'push' : q.append(op[1 ]) elif ch == 'empty' : print ('NO' if len (q) else 'YES' ) elif ch == 'pop' : q.pop(0 ) else : print (q[0 ]) main()
写法2:降低了时间复杂度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 q = [] def main(): hh,tt = 0,-1 num = int(input()) for i in range(num): op = input().split() ch = op[0] if ch == 'push': tt += 1 q.append(op[1]) elif ch == 'pop': hh += 1 elif ch == 'empty': print('NO' if tt>=hh else 'YES') else: print(q[hh]) main()
写法三:python库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from collections import dequedef main (): q = deque() num = int (input ()) for i in range (num): op = input ().split() if op[0 ] == 'push' : q.append(op[1 ]) elif op[0 ] == 'pop' : q.popleft() elif op[0 ] == 'empty' : print ('NO' if len (q) else 'YES' ) else : print (q[0 ]) main()
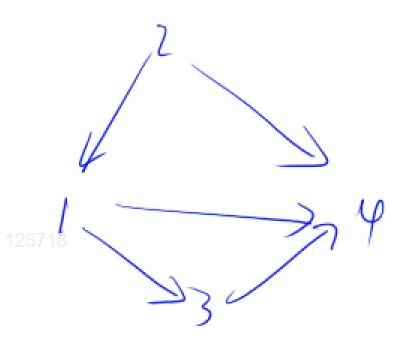
单调栈 若a[x]>=a[y]且x>y,则a[x]可以被替换为y,故如果用stk栈结构来存储一个数前面的数:
若当前数下标为5,目前栈内的数下标为1~4,由上述说法可知,左侧标的三个红色圈的数都是无效的,故可被替换为新的数,最终形成红色的线,实质上是维持栈中元素随着下标单调递增,不能出现下折或者直线的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> using namespace std;const int N = 100010 ;int stk[N], tt;int main () int n; cin >> n; while (n -- ) { int x; scanf ("%d" , &x); while (tt && stk[tt] >= x) tt -- ; if (!tt) printf ("-1 " ); else printf ("%d " , stk[tt]); stk[ ++ tt] = x; } return 0 ; }
python版本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 N = 100010 stk = [0 ]*N def main (): tt = -1 num = int (input ()) lst = list (map (int ,input ().split())) for i in range (num): while tt>=0 and stk[tt]>= lst[i]: tt -= 1 if tt < 0 : print (-1 ,end=' ' ) else : print (stk[tt],end=' ' ) tt += 1 stk[tt] = lst[i] main()
单调队列 滑动队列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> using namespace std;const int N=10000010 ;int a[N],q[N];int n,k;int main () scanf ("%d%d" ,&n,&k); for (int i=0 ;i<n;i++) { scanf ("%d" ,&a[i]); } int hh=0 ,tt=-1 ; for (int i=0 ;i<n;i++) { if (hh<=tt&&i-k+1 >q[hh]) hh++; while (hh<=tt&&a[q[tt]]>=a[i]) tt--; q[++tt]=i; if (i>=k-1 ) printf ("%d " ,a[q[hh]]); } puts ("" ); hh=0 ,tt=-1 ; for (int i=0 ;i<n;i++) { if (hh<=tt&&i-k+1 >q[hh]) hh++; while (hh<=tt&&a[q[tt]]<=a[i]) tt--; q[++tt]=i; if (i>=k-1 ) printf ("%d " ,a[q[hh]]); } return 0 ; }
python:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 N = 1000010 q = [0 ]*N def main (): hh,tt = 0 ,-1 n,k = map (int ,input ().split()) a = list (map (int ,input ().split())) res = [] for i in range (n): while tt>=hh and q[hh]<i-k+1 : hh += 1 while tt>=hh and a[q[tt]]>=a[i]: tt -= 1 tt += 1 q[tt] = i if i-k+1 >=0 : res.append(a[q[hh]]) print (' ' .join(map (str ,res))) res.clear() hh,tt = 0 ,-1 for i in range (n): while tt>=hh and q[hh]<i-k+1 : hh += 1 while tt>=hh and a[q[tt]]<=a[i]: tt -= 1 tt += 1 q[tt] = i if i-k+1 >=0 : res.append(a[q[hh]]) print (' ' .join(map (str ,res))) main()
deque:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from collections import dequeq = deque() res = [] def main (): n,k = map (int ,input ().split()) a = list (map (int ,input ().split())) for i in range (n): while len (q)>0 and i-k+1 >q[0 ]: q.popleft() while len (q)>0 and a[q[-1 ]]>=a[i]: q.pop() q.append(i) if i-k+1 >=0 : res.append(a[q[0 ]]) print (' ' .join(map (str ,res))) res.clear() q.clear() for i in range (n): while len (q)>0 and i-k+1 >q[0 ]: q.popleft() while len (q)>0 and a[q[-1 ]]<=a[i]: q.pop() q.append(i) if i-k+1 >=0 : res.append(a[q[0 ]]) print (' ' .join(map (str ,res))) main()
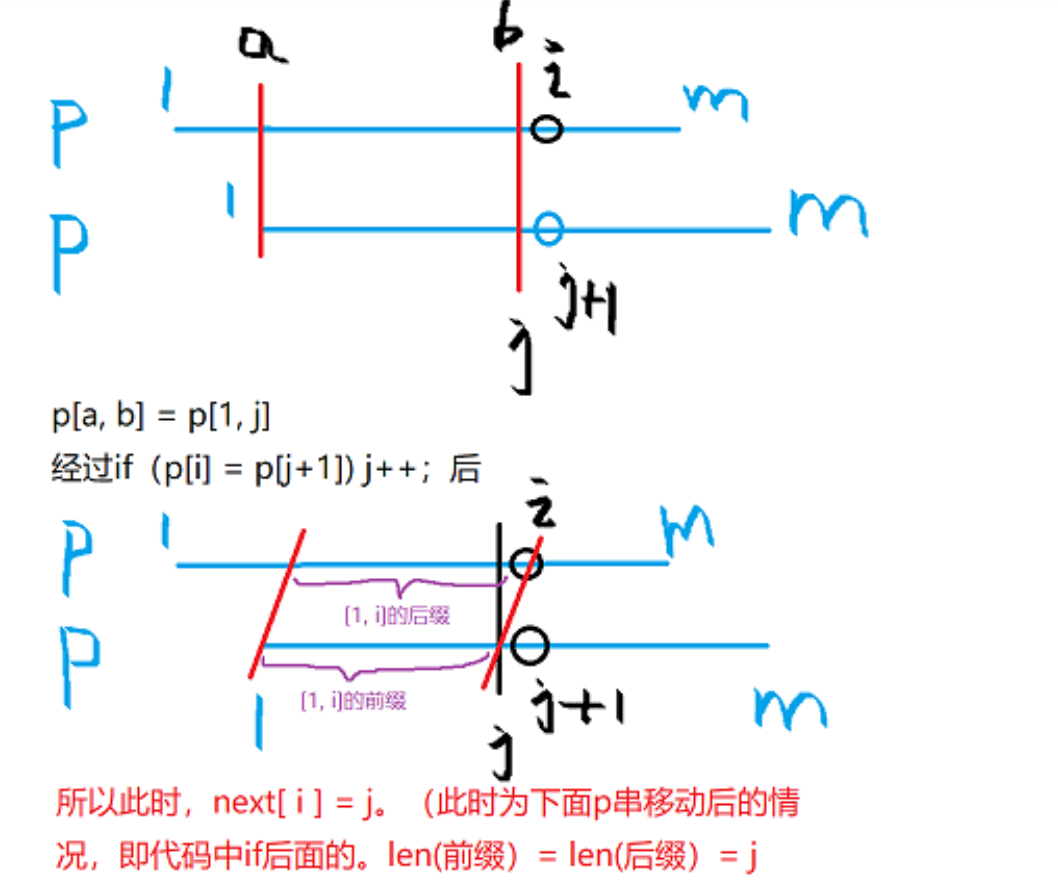
KMP 前后缀等长相等
p[1,j]=p[i-j+1,i]
首先明确前后缀的含义,然后明确next数组的含义
注意总是用i和j+1进行匹配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> using namespace std;const int N=1e6 +10 ;char p[N],s[N];int n,m;int ne[N];int main () cin>>n>>p+1 >>m>>s+1 ; for (int i=2 ,j=0 ;i<=n;i++) { while (j&&p[i]!=p[j+1 ]) j=ne[j]; if (p[i]==p[j+1 ]) j++; ne[i]=j; } for (int i=1 ,j=0 ;i<=m;i++) { while (j&&s[i]!=p[j+1 ]) j=ne[j]; if (s[i]==p[j+1 ]) j++; if (j==n) { cout<<i-n<<" " ; } } return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def main (): n = int (input ()) p = ' ' + input () m = int (input ()) s = ' ' + input () N = 100010 ne = [0 ] * N j = 0 for i in range (2 ,n+1 ): while j and p[i]!=p[j+1 ]: j = ne[j] if p[i] == p[j+1 ]: j += 1 ne[i] = j j = 0 for i in range (1 ,m+1 ): while j and s[i]!=p[j+1 ]: j = ne[j] if s[i] == p[j+1 ]: j += 1 if j == n: print (i-n+1 -1 ,end =' ' ) j = ne[j] main()
Trie
Trie:高效地存储和查找字符串,是一个集合的数据结构
Trie树中有个二维数组 son[N][26],表示当前结点的儿子,如果没有的话,可以等于++idx。Trie树本质上是一颗多叉树,对于字母而言最多有26个子结点。所以这个数组包含了两条信息。比如:son[1][0]=2表示1结点的一个值为a的子结点为结点2;如果son[1][0] = 0,则意味着没有值为a子结点。这里的son[N]/[26]相当于链表中的ne[N]。
1 2 3 4 5 6 7 8 9 10 11 void insert (char str[]) int p = 0 ; for (int i = 0 ; str[i]; i ++ ) { int u =str[i] - 'a' ; if (!son[p][u]) son[p][u] = ++ idx; p = son[p][u]; } cnt[p] ++; }
Trie树字符串统计 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <iostream> using namespace std;const int N=1e5 +10 ;int son[N][26 ],cnt[N],idx;int n;char str[N];void insert (char *str) int p=0 ; for (int i=0 ;str[i];i++) { int u=str[i]-'a' ; if (son[p][u]==0 ) son[p][u]=++idx; p=son[p][u]; } cnt[p]++; } int query (char *str) int p=0 ; for (int i=0 ;str[i];i++) { int u=str[i]-'a' ; if (son[p][u]==0 ) return 0 ; p=son[p][u]; } return cnt[p]; } int main () cin>>n; char op[2 ]; for (int i=0 ;i<n;i++) { scanf ("%s%s" ,op,str); if (*op=='I' ) insert (str); else printf ("%d\n" ,query (str)); } return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 N = 100010 son = [[0 ]*26 for _ in range (N)] cnt = [0 ]*N idx = 0 def insert (exp ): global idx p = 0 for ch in exp: u = ord (ch) - ord ('a' ) if son[p][u] == 0 : idx += 1 son[p][u] = idx p = son[p][u] cnt[p] += 1 def query (exp ): global idx p = 0 for ch in exp: u = ord (ch) - ord ('a' ) if son[p][u] == 0 : return 0 p = son[p][u] return cnt[p] def main (): n = int (input ()) for i in range (n): op,ch = input ().split() if op == 'I' : insert(ch) else : res = query(ch) print (res) main()
最大异或对 有点贪心的味道
这道题的启示是:字典树不单单可以高效存储和查找字符串集合,还可以存储二进制数字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <iostream> using namespace std;const int N=100010 ,M=3100010 ;int n;int son[M][2 ],idx,a[N];void insert (int x) int p=0 ; for (int i=30 ;i>=0 ;i--) { int u=x>>i&1 ; if (!son[p][u]) son[p][u]=++idx; p=son[p][u]; } } int search (int x) int p=0 ,res=0 ; for (int i=30 ;i>=0 ;i--) { int u=x>>i&1 ; if (son[p][!u]) { res+=1 <<i; p=son[p][!u]; }else p=son[p][u]; } return res; } int main () cin>>n; for (int i=0 ;i<n;i++) { cin>>a[i]; insert (a[i]); } int res=0 ; for (int i=0 ;i<n;i++) { res=max (res,search (a[i])); } cout<<res; return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 N = 3100010 son = [[0 ]*2 for _ in range (N)] idx = 0 def insert (exp ): global idx p = 0 for i in range (30 ,-1 ,-1 ): u = exp>>i&1 if son[p][u] == 0 : idx += 1 son[p][u] = idx p = son[p][u] def query (exp ): global idx p = 0 res = 0 for i in range (30 ,-1 ,-1 ): u = exp>>i&1 if son[p][1 ^u] == 0 : p = son[p][u] else : res += 1 <<i p = son[p][1 ^u] return res def main (): n = int (input ()) lst = list (map (int ,input ().split())) for item in lst: insert(item) res = 0 for item in lst: res = max (res,query(item)) print (res) main()
并查集 并查集:
将两个集合合并
询问两个元素是否在一个集合中
基本原理:每个集合用一棵树来表示。树根的编号就是整个集合的编号。每个节点存储他的父节点,p[x]表示x的父节点
问题一:如何判断树根:if(p[x]==x)
问题二:如何求x的集合编号:while(p[x]!=x) x=p[x];
问题三:如何合并两个集合:假设p[x]是x的集合编号,p[y]是y的集合编号。合并:p[x]=y
近乎O(1)的效率完成上述两个操作
优化——路径压缩:对问题二找根的过程进行优化,一旦往上走的过程中找到根节点,则把路径上所有节点的的根节点指向根(这样就能实现O(1))
合并集合 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <iostream> using namespace std;const int N=1e5 +10 ;int p[N];int find (int x) if (p[x]!=x) p[x]=find (p[x]); return p[x]; } int main () int n,m; cin>>n>>m; for (int i=1 ;i<=n;i++) p[i]=i; char op[2 ]; int a,b; while (m--) { scanf ("%s%d%d" ,op,&a,&b); if (*op=='M' ) p[find (a)]=find (b); else { if (find (a)==find (b)) cout<<"Yes\n" ; else cout<<"No\n" ; } } return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 N = 100010 p = [0 ]*N def find (x ): while p[x]!=x: p[x] = p[p[x]] x = p[x] return x def main (): n,m = map (int ,input ().split()) for i in range (1 ,n+1 ): p[i] = i for i in range (m): op,a,b = input ().split() a,b =int (a),int (b) if op == 'M' : p[find(a)] = find(b) else : if find(a) == find(b): print ('Yes' ) else : print ('No' ) main()
连通块中点的数量 与上题类似,不同之处需要记录数量,这里规定只有根节点的数量属性是有效的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <iostream> using namespace std;const int N=100010 ;int n,m;int p[N],cnt[N];int find (int x) if (p[x]!=x) p[x]=find (p[x]); return p[x]; } int main () cin>>n>>m; for (int i=1 ;i<=n;i++) { p[i]=i; cnt[i]=1 ; } while (m--) { string op; int a,b; cin>>op; if (op=="C" ) { cin>>a>>b; a=find (a),b=find (b); if (a!=b) { p[a]=b; cnt[b]+=cnt[a]; } } else if (op=="Q1" ) { cin>>a>>b; if (find (a)==find (b)) cout<<"Yes\n" ; else cout<<"No\n" ; }else { cin>>a; cout<<cnt[find (a)]<<endl; } } return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 N = 100010 p = [0 ]*N cnt = [1 ]*N def find (x ): while p[x]!=x: p[x] = p[p[x]] x = p[x] return p[x] def main (): n,m = map (int ,input ().split()) for i in range (1 ,n+1 ): p[i] = i for i in range (m): op = input ().split() if op[0 ] == 'C' : a = find(int (op[1 ])) b = find(int (op[2 ])) if a!=b: p[a] = b cnt[b] += cnt[a] elif op[0 ] == 'Q1' : if find(int (op[1 ])) == find(int (op[2 ])): print ('Yes' ) else : print ('No' ) else : print (cnt[find(int (op[1 ]))]) main()
食物链
find(x)有两个功能: 1 路径压缩, 2 更新 d[x]
这道题的插入方式需要注意,且使用距离来体现与根节点的关系,d%3的情况如下:
=0,则与根节点同类型
=1,一层节点,可以吃掉根节点,可以被二层节点吃
=2,二层节点,可以吃掉一层节点,可以被零层节点(根节点同类型)吃
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 #include <iostream> using namespace std;const int N=50010 ;int n,m;int p[N],d[N];int find (int x) if (p[x]!=x) { int t=find (p[x]); d[x]+=d[p[x]]; p[x]=t; } return p[x]; } int main () scanf ("%d%d" ,&n,&m); for (int i=1 ;i<=n;i++) p[i]=i; int res=0 ; while (m--) { int t,x,y; scanf ("%d%d%d" ,&t,&x,&y); if (x>n||y>n) res++; else { int px=find (x),py=find (y); if (t==1 ) { if (px==py&&(d[x]-d[y])%3 ) res++; else if (px!=py) { p[px]=py; d[px]=d[y]-d[x]; } } else { if (px==py&&(d[x]-d[y]-1 )%3 ) res++; else if (px!=py) { p[px]=py; d[px]=d[y]+1 -d[x]; } } } } printf ("%d\n" ,res); return 0 ; }
另外一种更加容易理解的做法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 def main (): n, k = map (int , input ().split()) parent = [i for i in range (n + 1 )] relation = [0 ] * (n + 1 ) false_count = 0 def find (x ): if parent[x] != x: original_parent = parent[x] parent[x] = find(parent[x]) relation[x] = (relation[x] + relation[original_parent]) % 3 return parent[x] def union (x, y, d ): root_x = find(x) root_y = find(y) if root_x == root_y: if (relation[x] - relation[y] + 3 ) % 3 != d - 1 : return False else : return True else : parent[root_x] = root_y relation[root_x] = (relation[y] - relation[x] + d - 1 + 3 ) % 3 return True for _ in range (k): d, x, y = map (int , input ().split()) if x > n or y > n: false_count += 1 continue if d == 2 and x == y: false_count += 1 continue if not union(x, y, d): false_count += 1 print (false_count) if __name__ == "__main__" : main()
整理一下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 N = 50010 p = [0 ] * N r = [0 ] * N def find (x ): if p[x] != x: p_x = p[x] p[x] = find(p[x]) r[x] = (r[x] + r[p_x] + 3 ) % 3 return p[x] def union (op, a, b ): ra = find(a) rb = find(b) if ra == rb: if (r[a] - r[b] + 3 ) % 3 != op - 1 : return False else : return True else : p[ra] = rb r[ra] = (r[b] - r[a] + op - 1 + 3 ) % 3 return True def main (): n, k = map (int , input ().split()) res = 0 for i in range (1 , n + 1 ): p[i] = i for i in range (k): op, a, b = map (int , input ().split()) if a > n or b > n: res += 1 elif op == 2 and a == b: res += 1 elif not union(op, a, b): res += 1 print (res) main()
堆 如何手写一个堆?
插入一个数
求集合当中的最小值
删除最小值
删除任意一个元素
修改任意一个元素
堆——完全二叉树,除了最后一排节点都是非空的,最后一排节点从左到右排列
小根堆——每个点都是小于左右儿子的(可知根节点是堆里面的最小值)
存储方式:
1(根节点)
2(根节点左儿子)
3(根节点右儿子)
4
5
节点x的左儿子:2x
节点x的右儿子:2x+1
堆排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <iostream> using namespace std;int const N = 100010 ;int h[N], siz; void down (int u) int t = u; if (u * 2 <= siz && h[u * 2 ] < h[t]) t = u * 2 ; if (u * 2 + 1 <= siz && h[u * 2 + 1 ] < h[t]) t = u * 2 + 1 ; if (t != u) { swap (h[t], h[u]); down (t); } } int main () int n, m; cin >> n >> m; for (int i = 1 ; i <= n; i ++ ) scanf ("%d" , &h[i]); siz = n; for (int i = n / 2 ; i; i --) down (i); while (m -- ) { printf ("%d " , h[1 ]); h[1 ] = h[siz]; siz --; down (1 ); } return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 N = 100010 h = [0 ]*N siz = 0 def down (u ): global siz t = u if 2 *u<=siz and h[2 *u]<h[t]: t = 2 *u if 2 *u+1 <=siz and h[2 *u+1 ]<h[t]: t = 2 *u + 1 if t!=u: h[t],h[u] = h[u],h[t] down(t) def main (): global siz n,m = map (int ,input ().split()) siz = n h[1 :n+1 ] = list (map (int ,input ().split())) for i in range (n//2 ,0 ,-1 ): down(i) for i in range (m): print (h[1 ],end =' ' ) h[1 ] = h[siz] siz -= 1 down(1 ) main()
模拟堆 由于题目要求修改和删除第k个插入的,所以要加入存储映射,为了便于在up、down过程中修改映射,需要两个数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 #include <iostream> #include <string.h> #include <algorithm> using namespace std;const int N=100010 ;int h[N],ph[N],hp[N],cnt;void heap_swap (int a,int b) swap (ph[hp[a]],ph[hp[b]]); swap (hp[a],hp[b]); swap (h[a],h[b]); } void down (int u) int t=u; if (u*2 <=cnt&&h[u*2 ]<h[t]) t=u*2 ; if (u*2 +1 <=cnt&&h[u*2 +1 ]<h[t]) t=u*2 +1 ; if (u!=t) { heap_swap (u,t); down (t); } } void up (int u) while (u/2 &&h[u]<h[u/2 ]) { heap_swap (u,u/2 ); u>>=1 ; } } int main () int n,m=0 ; scanf ("%d" ,&n); while (n--) { char op[5 ]; int k,x; scanf ("%s" ,op); if (!strcmp (op,"I" )) { scanf ("%d" ,&x); cnt++; m++; ph[m]=cnt,hp[cnt]=m; h[cnt]=x; up (cnt); } else if (!strcmp (op,"PM" )) printf ("%d\n" ,h[1 ]); else if (!strcmp (op,"DM" )) { heap_swap (1 ,cnt); cnt--; down (1 ); }else if (!strcmp (op,"D" )) { scanf ("%d" ,&k); k=ph[k]; heap_swap (k,cnt); cnt--; up (k); down (k); } else { scanf ("%d%d" ,&k,&x); k=ph[k]; h[k]=x; up (k); down (k); } } return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 N = 100010 h = [0 ]*N hp = [0 ]*N ph = [0 ]*N cnt = 0 def swap (a,b ): ph[hp[a]],ph[hp[b]] = ph[hp[b]],ph[hp[a]] hp[a],hp[b] = hp[b],hp[a] h[a],h[b] = h[b],h[a] def up (u ): while u//2 and h[u]<h[u//2 ]: swap(u,u//2 ) u = u//2 def down (u ): global cnt t = u if u*2 <=cnt and h[u*2 ]<h[t]: t = u*2 if u*2 +1 <=cnt and h[u*2 +1 ]<h[t]: t = u*2 +1 if t!=u: swap(u,t) down(t) def main (): global cnt n = int (input ()) m = 0 for i in range (n): op = input ().split() if op[0 ] == 'I' : x = int (op[1 ]) cnt += 1 m += 1 h[cnt] = x ph[m] = cnt hp[cnt] = m up(cnt) elif op[0 ] == 'PM' : print (h[1 ]) elif op[0 ] == 'DM' : swap(1 ,cnt) cnt -= 1 down(1 ) elif op[0 ] =='D' : k = int (op[1 ]) idx = ph[k] swap(idx,cnt) cnt -= 1 down(idx) up(idx) else : k,x = map (int ,op[1 :]) idx = ph[k] h[idx] = x down(idx) up(idx) main()
哈希表 模拟散列表 求质数的方法:
关于哈希函数对应的数组的大小:如果用拉链法,则和数多少差不多即可,如果用开放寻址法,则设置为该数的两倍
开放寻址法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <iostream> #include <cstring> using namespace std;const int N=200003 ,null=0x3f3f3f3f ;int h[N];int find (int x) int t=(x%N+N)%N; while (h[t]!=null&&h[t]!=x) { t++; if (t==N) t=0 ; } return t; } int main () memset (h,0x3f ,sizeof h); int n; scanf ("%d" ,&n); string op; int x; while (n--) { cin>>op>>x; if (op=="I" ) h[find (x)]=x; else { if (h[find (x)]==null) puts ("No" ); else puts ("Yes" ); } } return 0 ; }
拉链法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <cstring> #include <iostream> using namespace std;const int N=100003 ;int h[N],e[N],ne[N],idx;void insert (int x) int k=(x%N+N)%N; e[idx]=x; ne[idx]=h[k]; h[k]=idx++; } bool find (int x) int k=(x%N+N)%N; for (int i=h[k];i!=-1 ;i=ne[i]) { if (e[i]==x) return true ; } return false ; } int main () int n; scanf ("%d" ,&n); memset (h,-1 ,sizeof h); while (n--) { string op; int x; cin>>op>>x; if (op=="I" ) insert (x); else { if (find (x)) puts ("Yes" ); else puts ("No" ); } } return 0 ; }
python的defaultdict
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from collections import defaultdictdef main (): d = defaultdict(int ) n = int (input ()) for i in range (n): op = input ().split() num = int (op[1 ]) if op[0 ] == 'I' : d[num] += 1 else : if d[num] == 0 : print ('No' ) else : print ('Yes' ) main()
拉链法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 N = 100003 h = [-1 ]*N e = [0 ]*N ne = [0 ]*N idx = 0 def insert (num ): global idx k = num%N e[idx] = num ne[idx] = h[k] h[k] = idx idx += 1 def find (num ): k = num%N i = h[k] while i!=-1 : if e[i] == num: return True i = ne[i] return False def main (): n = int (input ()) for i in range (n): op = input ().split() num = int (op[1 ]) if op[0 ] == 'I' : insert(num) else : if find(num): print ('Yes' ) else : print ('No' ) main()
寻址法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 N = 200003 null = 0x3f3f3f3f h = [null]*N def find (x ): k = x % N while h[k]!=null and h[k]!=x: k += 1 if k == N: k = 0 return k def main (): n = int (input ()) for i in range (n): op = input ().split() num = int (op[1 ]) if op[0 ] == 'I' : k = find(num) h[k] = num else : k = find(num) if h[k]!=null: print ('Yes' ) else : print ('No' ) main()
字符串哈希 前求字符串的前缀哈希值
h[i]字符串前i位字符串对应的哈希值
我们将字符串当做一个p进制的数来看待
在字符串哈希中,我们没有处理冲突,靠经验定理来保证不冲突,将字符串看做是p进制的数
根据经验定理,p取131或者1331,得到的数模上2的64次方,可保证完全散列,由于数据类型unsigned int的值域恰好为2的64次方,故可以直接使用unsigned int存储,溢出即为取模
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <iostream> #include <algorithm> using namespace std;typedef unsigned long long ULL;const int N=100010 ,P=131 ;int n,m;char str[N];ULL h[N],p[N]; ULL get (int l,int r) return h[r]-h[l-1 ]*p[r-l+1 ]; } int main () scanf ("%d%d" ,&n,&m); scanf ("%s" ,str+1 ); p[0 ]=1 ; for (int i=1 ;i<=n;i++) { h[i]=h[i-1 ]*P+str[i]; p[i]=p[i-1 ]*P; } while (m--) { int l1,r1,l2,r2; scanf ("%d%d%d%d" ,&l1,&r1,&l2,&r2); if (get (l1,r1)==get (l2,r2)) { puts ("Yes" ); }else puts ("No" ); } return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 N = 100010 P = 131 Q = 1 <<64 h = [0 ]*N p = [0 ]*N def find (l,r ): return (h[r] - h[l-1 ]*p[r-l+1 ])%Q def main (): global P global Q p[0 ] = 1 n,m = map (int ,input ().split()) s = ' ' + input () for i in range (1 ,n+1 ): h[i] = (h[i-1 ]*P + ord (s[i]))%Q p[i] = p[i-1 ]*P % Q for i in range (m): l1,r1,l2,r2 = map (int ,input ().split()) if find(l1,r1) == find(l2,r2): print ('Yes' ) else : print ('No' ) main()
搜索与图论 1.DFS:递归结束条件的选择+状态标记+递归后的恢复
点的数量和边的数量,若点的数量的平方与边的数量大致相同,则为稠密图
邻接矩阵去重边用min,邻接表里面无需去重边
无向图存储的时候边的数量要开成给定边数量的一倍大小
DFS 排列数字 典型排列树,但是需要按照字典序来做,下面这种做法会有些不同
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <iostream> using namespace std;const int N=10 ;int x[N];int n;void DFS (int t) if (t==n) { for (int i=1 ;i<=n;i++) cout<<x[i]<<" " ; puts ("" ); return ; } for (int i=t;i<=n;i++) { swap (x[i],x[t]); DFS (t+1 ); swap (x[i],x[t]); } } int main () cin>>n; for (int i=1 ;i<=n;i++) x[i]=i; DFS (1 ); return 0 ; }
acwing提供的做法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> using namespace std;const int N=10 ;int n;int path[N];void dfs (int u,int state) if (u==n) { for (int i=0 ;i<n;i++) printf ("%d " ,path[i]); puts ("" ); return ; } for (int i=0 ;i<n;i++) { if (!(state>>i&1 )) { path[u]=i+1 ; dfs (u+1 ,state+(1 <<i)); } } } int main () scanf ("%d" ,&n); dfs (0 ,0 ); return 0 ; }
n皇后问题 排列树,dg和udg用来判断是否在对角线上有冲突,主对角线检查下标y-x+n是否冲突,副对角线检查x+y是否冲突
同时由于对角线数量是n的两倍左右,N数量要开两倍
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <iostream> using namespace std;const int N=20 ;int x[N],dg[N],udg[N],n;void backtrack (int t) if (t>n) { for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=n;j++) { if (j==x[i]) printf ("Q" ); else printf ("." ); } puts ("" ); } puts ("" ); return ; } for (int i=t;i<=n;i++) { swap (x[i],x[t]); if (!dg[t+x[t]]&&!udg[n+x[t]-t]) { dg[t+x[t]]=udg[n+x[t]-t]=1 ; backtrack (t+1 ); dg[t+x[t]]=udg[n+x[t]-t]=0 ; } swap (x[i],x[t]); } } int main () cin>>n; for (int i=1 ;i<=n;i++) { x[i]=i; } backtrack (1 ); return 0 ; }
acwing解法,差不多
BFS 分支限界框架
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 queue Q; int bestw;Node k=new node (); set k; Q.push (k); while (!Q.empty ()){ Node cn = Q.pop (); int level=cn.level; if (level>n){ print (); break ; } for (auto node:cn的后继) { if (约束函数/限界函数) { Node tmp = new Node (); set tmp; Q.push () } } }
BFS相对而言更简单,通常无需考虑level和一些剪枝
走迷宫 首先用回溯法做了一遍,果然超时了,回溯剪枝不够强大
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <iostream> #include <cstring> using namespace std;const int N=105 ;int a[N][N];int n,m;int cw,cbest=10000 ;void dfs (int x,int y) if (x==n&&y==m) { if (cw<cbest) cbest=cw; return ; } if (cw>cbest) return ; a[x][y]=1 ; cw++; if (!a[x][y-1 ]) dfs (x,y-1 ); if (!a[x][y+1 ]) dfs (x,y+1 ); if (!a[x+1 ][y]) dfs (x+1 ,y); if (!a[x-1 ][y]) dfs (x-1 ,y); a[x][y]=0 ; cw--; } int main () cin>>n>>m; memset (a,1 ,sizeof a); for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=m;j++) { cin>>a[i][j]; } } dfs (1 ,1 ); cout<<cbest; return 0 ; }
遂使用可爱的BFS!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <iostream> #include <cstring> #include <algorithm> #include <queue> using namespace std;const int N=110 ;typedef pair<int ,int > PII;int n,m;int g[N][N],d[N][N];int bfs () queue<PII> q; memset (d,-1 ,sizeof (d)); d[0 ][0 ]=0 ; q.push ({0 ,0 }); int dx[4 ]={-1 ,0 ,1 ,0 },dy[4 ]={0 ,1 ,0 ,-1 }; while (q.size ()) { auto t=q.front (); q.pop (); for (int i=0 ;i<4 ;i++) { int x=t.first+dx[i]; int y=t.second+dy[i]; if (x>=0 &&x<n&&y>=0 &&y<m&&g[x][y]==0 &&d[x][y]==-1 ) { d[x][y]=d[t.first][t.second]+1 ; q.push ({x,y}); } } } return d[n-1 ][m-1 ]; } int main () cin>>n>>m; for (int i=0 ;i<n;i++) { for (int j=0 ;j<m;j++) { cin>>g[i][j]; } } cout<<bfs ()<<endl; return 0 ; }
八数码 主要难点在于状态的表示和转换上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 #include <iostream> #include <algorithm> #include <unordered_map> #include <queue> using namespace std;int bfs (string state) queue<string> q; unordered_map<string,int > d; q.push (state); d[state]=0 ; int dx[4 ]={-1 ,0 ,1 ,0 },dy[4 ]={0 ,-1 ,0 ,1 }; string end="12345678x" ; while (q.size ()) { auto t=q.front (); q.pop (); if (t==end) return d[t]; int distance=d[t]; int k=t.find ('x' ); int x=k/3 ,y=k%3 ; for (int i=0 ;i<4 ;i++) { int a=x+dx[i],b=y+dy[i]; if (a>=0 &&a<3 &&b>=0 &&b<3 ) { swap (t[a*3 +b],t[k]); if (!d.count (t)) { d[t]=distance+1 ; q.push (t); } swap (t[3 *a+b],t[k]); } } } return -1 ; } int main () char s[2 ]; string state; for (int i=0 ;i<9 ;i++) { cin>>s; state+=*s; } cout<<bfs (state)<<endl; return 0 ; }
树与图的深度优先遍历 树和图的存储方式,树是特殊的图,故介绍图的存储方式
图:有向图、无向图
有向图:a->b
无向图:a->b,b->a
故只需要考虑有向图的存储方式
领接矩阵:a->b,g[a][b]=w,记录边权,不能存储重边(a->b有多条边,但也可以直接选一条)
邻接表:
(数组建立邻接表) 树/图的dfs
1 2 3 4 5 6 7 8 9 int h[N], e[N * 2 ], ne[N * 2 ], idx;void add (int a, int b) e[idx] = b, ne[idx] = h[a], h[a] = idx++; } int main () memset (h,-1 ,sizeof h); }
树/图的bfs模板
1 2 3 4 5 6 7 8 9 10 void dfs (int u) st[u] = true ; for (int i = h[u]; i != -1 ; i = ne[i]) { int j = e[i]; if (!st[j]) { dfs (j); } } }
树的重心 本题的本质是树的dfs, 每次dfs可以确定以u为重心的最大连通块的节点数,并且更新一下ans。
也就是说,dfs并不直接返回答案,而是在每次更新中迭代一次答案。
这样的套路会经常用到,在 树的dfs 题目中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <iostream> #include <cstring> using namespace std;const int N=100010 ,M=2 *N;int n;int h[N],e[M],ne[M],idx;int ans=N;bool st[N];void add (int a,int b) e[idx]=b,ne[idx]=h[a],h[a]=idx++; } int dfs (int u) st[u]=true ; int size=0 ,sum=0 ; for (int i=h[u];i!=-1 ;i=ne[i]) { int j=e[i]; if (st[j]) continue ; int s=dfs (j); size=max (size,s); sum+=s; } size=max (size,n-sum-1 ); ans=min (ans,size); return sum+1 ; } int main () scanf ("%d" ,&n); memset (h,-1 ,sizeof h); for (int i=0 ;i<n-1 ;i++) { int a,b; scanf ("%d%d" ,&a,&b); add (a,b),add (b,a); } dfs (1 ); printf ("%d\n" ,ans); return 0 ; }
树与图的广度优先遍历 图中点的层次 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 #include <cstdio> #include <cstring> #include <iostream> #include <algorithm> #include <queue> using namespace std;const int N = 100010 ;int n, m;int h[N], e[N], ne[N], idx;int d[N];void add (int a, int b) e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ; } int bfs () memset (d, -1 , sizeof d); queue<int > q; d[1 ] = 0 ; q.push (1 ); while (q.size ()) { int t = q.front (); q.pop (); for (int i = h[t]; i != -1 ; i = ne[i]) { int j = e[i]; if (d[j] == -1 ) { d[j] = d[t] + 1 ; q.push (j); } } } return d[n]; } int main () scanf ("%d%d" , &n, &m); memset (h, -1 , sizeof h); for (int i = 0 ; i < m; i ++ ) { int a, b; scanf ("%d%d" , &a, &b); add (a, b); } cout << bfs () << endl; return 0 ; }
拓扑排序 有向图的拓扑序列 有向图才有拓扑序,并非所有图都有拓扑序列,有向无环图一定存在一个入度为0的点,一定存在拓扑序列
所谓拓扑序列,要求A->B,A在拓扑序列中要求排列在B前面,所有的边都由前指向后
可所有知入度为0的节点可作为拓扑序列的最前位置,思路如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> #include <cstring> using namespace std;const int N=100010 ;int n,m;int h[N],e[N],ne[N],idx;int d[N];int q[N];void add (int a,int b) e[idx]=b,ne[idx]=h[a],h[a]=idx++; } bool topsort () int hh=0 ,tt=-1 ; for (int i=1 ;i<=n;i++) { if (!d[i]) q[++tt]=i; } while (hh<=tt) { int t=q[hh++]; for (int i=h[t];i!=-1 ;i=ne[i]) { int j=e[i]; if (--d[j]==0 ) { q[++tt]=j; } } } return tt==n-1 ; } int main () cin>>n>>m; memset (h,-1 ,sizeof h); int a,b; for (int i=0 ;i<m;i++) { cin>>a>>b; add (a,b); d[b]++; } if (!topsort ()) puts ("-1" ); else { for (int i=0 ;i<n;i++) printf ("%d " ,q[i]); puts ("" ); } return 0 ; }
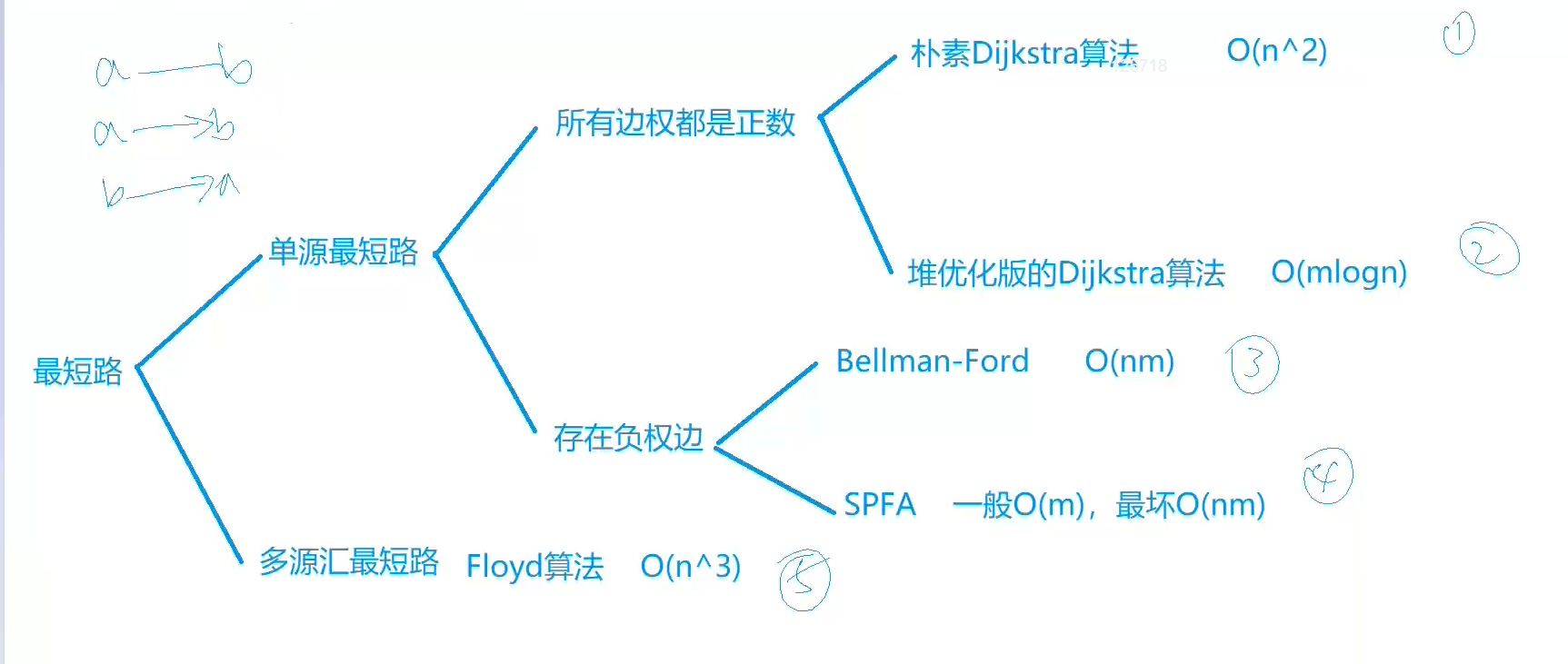
Dijkstra 稠密图用领接矩阵,稀疏图用邻接链表
朴素版本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <cstring> #include <iostream> #include <algorithm> using namespace std;const int N = 510 ;int n, m;int g[N][N];int dist[N];bool st[N];int dijkstra () memset (dist, 0x3f , sizeof dist); dist[1 ] = 0 ; for (int i = 0 ; i < n - 1 ; i ++ ) { int t = -1 ; for (int j = 1 ; j <= n; j ++ ) if (!st[j] && (t == -1 || dist[t] > dist[j])) t = j; for (int j = 1 ; j <= n; j ++ ) dist[j] = min (dist[j], dist[t] + g[t][j]); st[t] = true ; } if (dist[n] == 0x3f3f3f3f ) return -1 ; return dist[n]; } int main () scanf ("%d%d" , &n, &m); memset (g, 0x3f , sizeof g); while (m -- ) { int a, b, c; scanf ("%d%d%d" , &a, &b, &c); g[a][b] = min (g[a][b], c); } printf ("%d\n" , dijkstra ()); return 0 ; }
最小堆优化 priority_queue的定义方法如下所示:
1 2 3 4 priority_queue<int ,vector<int >,greater<int >> q; priority_queue<int ,vector<int >,less<int >> q; priority_queue<PII,vector<PII>,greater<PII>> heap;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <iostream> #include <cstring> #include <queue> using namespace std;typedef pair<int ,int > PII;const int N=1e6 +10 ;int n,m;int h[N],w[N],e[N],ne[N],idx;int dist[N];bool st[N];void add (int a,int b,int c) e[idx]=b,w[idx]=c,ne[idx]=h[a],h[a]=idx++; } int dijkstra () memset (dist,0x3f ,sizeof dist); dist[1 ]=0 ; priority_queue<PII,vector<PII>,greater<PII>> heap; heap.push ({0 ,1 }); while (heap.size ()) { auto t=heap.top (); heap.pop (); int ver=t.second,distance=t.first; if (st[ver]) continue ; st[ver]=true ; for (int i=h[ver];i!=-1 ;i=ne[i]) { int j=e[i]; if (dist[j]>dist[ver]+w[i]) { dist[j]=dist[ver]+w[i]; heap.push ({dist[j],j}); } } } if (dist[n]==0x3f3f3f3f ) return -1 ; return dist[n]; } int main () scanf ("%d%d" ,&n,&m); memset (h,-1 ,sizeof h); int a,b,c; while (m--) { scanf ("%d%d%d" ,&a,&b,&c); add (a,b,c); } printf ("%d" ,dijkstra ()); return 0 ; }
bellman-ford 可以处理负权重的情况,可以检测负环但是时间复杂度较高
串联:由于这个算法的特性决定,每次更新得到的必然是在多考虑 1 条边之后能得到的全局的最短路。而串联指的是一次更新之后考虑了不止一条边:由于使用了松弛,某节点的当前最短路依赖于其所有入度的节点的最短路;假如在代码中使用dist[e.b]=min(dist[e.b],dist[e.a] + e.c);,我们无法保证dist[e.a]是否也在本次循环中被更新,如果被更新了,并且dist[e.b] > dist[e.a] + e.c,那么会造成当前节点在事实上“即考虑了一条从某个节点指向a的边,也考虑了a->b”,共两条边。而使用dist[e.b]=min(dist[e.b],last[e.a] + e.c);,可以保证a在dist更新后不影响对b的判定,因为后者使用last数组,保存着上一次循环中的dist的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <cstring> #include <iostream> using namespace std;const int N=510 ,M=10010 ;struct Edge { int a,b,c; }edges[M]; int n,m,k;int dist[N];int last[N];void bellman_ford () memset (dist,0x3f ,sizeof dist); dist[1 ]=0 ; for (int i=0 ;i<k;i++) { memcpy (last,dist,sizeof dist); for (int j=0 ;j<m;j++) { auto e=edges[j]; dist[e.b]=min (dist[e.b],last[e.a]+e.c); } } } int main () scanf ("%d%d%d" ,&n,&m,&k); int a,b,c; for (int i=0 ;i<m;i++) { scanf ("%d%d%d" ,&a,&b,&c); edges[i]={a,b,c}; } bellman_ford (); if (dist[n]>0x3f3f3f3f /2 ) puts ("impossible" ); else printf ("%d" ,dist[n]); return 0 ; }
spfa 改进bellman_ford算法,dist[v]=dist[w]+w仅当前面的节点w的dist发生变化才更新,具体而言需要用广搜来做
还是基于bellman方程来做的,但是只动态加入前继节点改变的后继:dist[x]=dist[t]+w[i]
spfa求最短路 AcWing 851. SPFA算法 - AcWing
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 #include <iostream> #include <cstring> #include <queue> using namespace std;const int N=1e6 +10 ;int n,m;int h[N],ne[N],w[N],e[N],idx;int dist[N];bool st[N];void add (int a,int b,int c) e[idx]=b,ne[idx]=h[a],w[idx]=c,h[a]=idx++; } int spfa () memset (dist,0x3f ,sizeof dist); dist[1 ]=0 ; queue<int > q; q.push (1 ); st[1 ]=true ; while (q.size ()) { int t=q.front (); q.pop (); st[t]=false ; for (int i=h[t];i!=-1 ;i=ne[i]) { int j=e[i]; if (dist[j]>dist[t]+w[i]) { dist[j]=dist[t]+w[i]; if (!st[j]) { q.push (j); st[j]=true ; } } } } return dist[n]; } int main () memset (h,-1 ,sizeof h); scanf ("%d%d" ,&n,&m); int a,b,c; for (int i=0 ;i<m;i++) { scanf ("%d%d%d" ,&a,&b,&c); add (a,b,c); } int t=spfa (); if (t==0x3f3f3f3f ) printf ("impossible" ); else printf ("%d" ,t); return 0 ; }
spfa判断负环 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 #include <iostream> #include <cstring> #include <queue> using namespace std;const int N=2010 ,M=10010 ;int n,m;int h[N],ne[M],w[M],e[M],idx;bool st[N];int dist[N],cnt[N];void add (int a,int b,int c) e[idx]=b,ne[idx]=h[a],w[idx]=c,h[a]=idx++; } bool spfa () queue<int > q; for (int i=1 ;i<=n;i++) { st[i]=true ; q.push (i); } while (q.size ()) { int t=q.front (); q.pop (); st[t]=false ; for (int i=h[t];i!=-1 ;i=ne[i]) { int j=e[i]; if (dist[j]>dist[t]+w[i]) { dist[j]=dist[t]+w[i]; cnt[j]=cnt[t]+1 ; if (cnt[j]>=n) return true ; if (!st[j]) { st[j]=true ; q.push (j); } } } } return false ; } int main () scanf ("%d%d" ,&n,&m); int a,b,c; memset (h,-1 ,sizeof h); for (int i=1 ;i<=m;i++) { scanf ("%d%d%d" ,&a,&b,&c); add (a,b,c); } if (spfa ()) puts ("Yes" ); else puts ("No" ); return 0 ; }
问题一:为什么dt数组不用初始化为0x3f3f3f3f,以及为什么初始化要把所有点入队?
Floyd Floyd求最短路 三重循环!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <iostream> #include <cstring> using namespace std;const int N=210 ,INF=1e9 ;int n,m,Q;int d[N][N];void floyd () for (int k=1 ;k<=n;k++) { for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=n;j++) { d[i][j]=min (d[i][j],d[i][k]+d[k][j]); } } } } int main () scanf ("%d%d%d" ,&n,&m,&Q); for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=n;j++) { if (i==j) d[i][j]=0 ; else d[i][j]=INF; } } while (m--) { int a,b,c; scanf ("%d%d%d" ,&a,&b,&c); d[a][b]=min (d[a][b],c); } floyd (); while (Q--) { int a,b; scanf ("%d%d" ,&a,&b); int t=d[a][b]; if (t>INF/2 ) puts ("impossible" ); else printf ("%d\n" ,t); } return 0 ; }
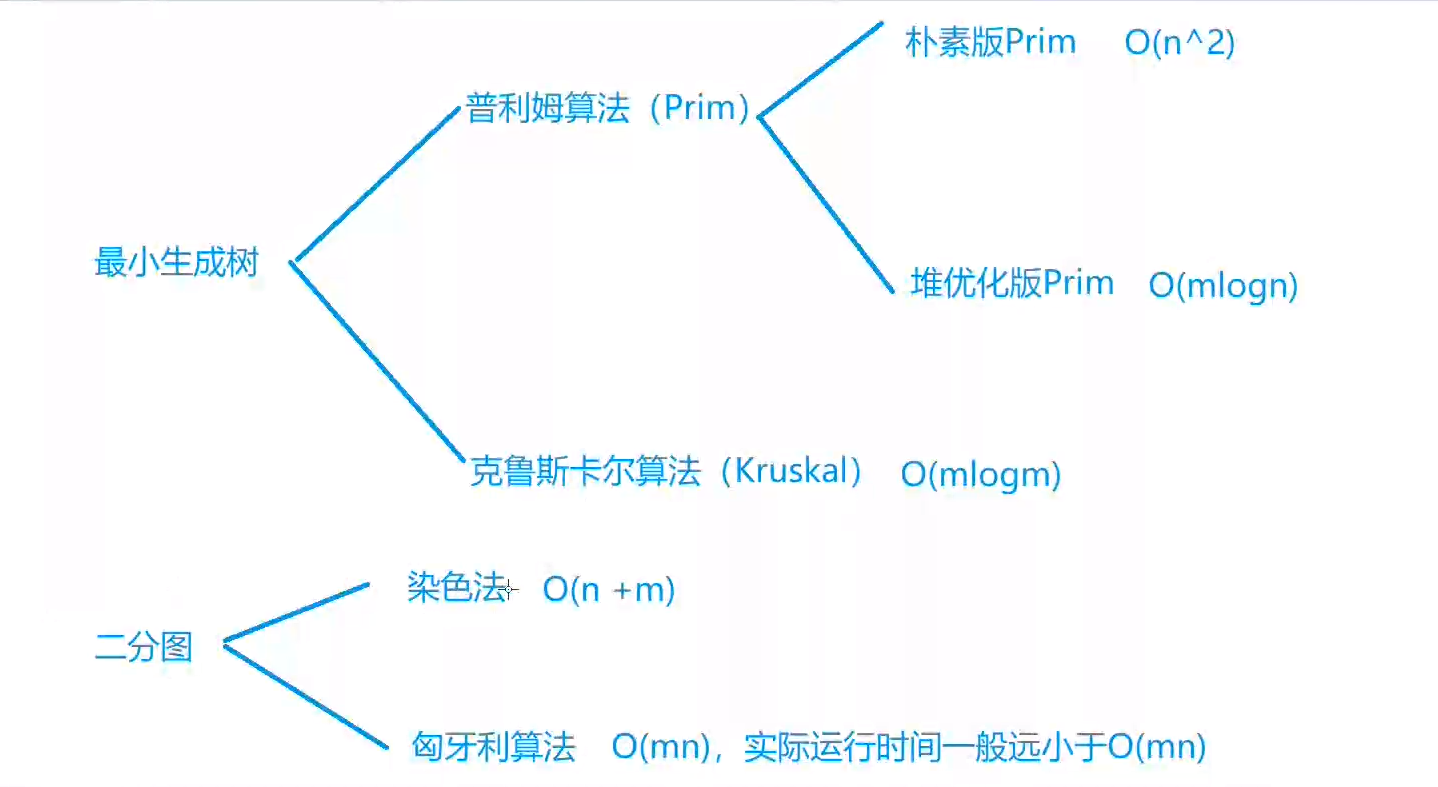
Prim算法 Prim算法求最小生成数 朴素版本:类似于dijkstra算法
思路:
与dijkstra不同,prim需要迭代n次
最小生成树是针对无向图的,所以在读入边的时候,需要赋值两次
要先累加再更新,避免t有自环,影响答案的正确性。后更新不会影响后面的结果么?不会的,因为dist[i]为i到集合S的距离,当t放入集合后,其dist[t]就已经没有意义了,再更新也不会影响答案的正确性。
需要特判一下第一次迭代,在我们没有做特殊处理时,第一次迭代中所有点到集合S的距离必然为无穷大,而且不会进行更新(也没有必要),所以不需要将这条边(第一次迭代时,找到的距离集合S最短的边)累加到答案中,也不能认定为图不连通。
如果需要设置起点为i的话,在初始化dist数组之后,dist[i] = 0即可,这样也可以省去每轮迭代中的两个if判断。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <iostream> #include <cstring> using namespace std;const int N=510 ,INF=0x3f3f3f3f ;int g[N][N],dist[N],n,m;bool st[N];int prim () memset (dist,0x3f ,sizeof dist); dist[1 ]=0 ; int res=0 ; for (int i=0 ;i<n;i++) { int t=-1 ; for (int j=1 ;j<=n;j++) { if (!st[j]&&(t==-1 ||dist[j]<dist[t])) { t=j; } } if (dist[t]==0x3f3f3f3f ) return 0x3f3f3f3f ; res+=dist[t]; st[t]=true ; for (int i=1 ;i<=n;i++) dist[i]=min (dist[i],g[t][i]); } return res; } int main () scanf ("%d%d" ,&n,&m); memset (g,0x3f ,sizeof g); int a,b,c; while (m--) { scanf ("%d%d%d" ,&a,&b,&c); g[a][b]=g[b][a]=min (g[a][b],c); } int t=prim (); if (t==0x3f3f3f3f ) puts ("impossible" ); else printf ("%d\n" ,t); return 0 ; }
Kruskal算法 求最小生成数
将所有边按权重从小到大排序 $O(nlogn)$
枚举每条边a,b,权重c;ifa,b不连通,将这条边也加入集合(并查集的使用) $(1)$
稀疏图里用kruskal
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> #include <cstring> #include <algorithm> using namespace std;const int N=100010 ,M=200010 ,INF=0x3f3f3f3f ;int n,m;int p[N];struct Edge { int a,b,w; bool operator <(const Edge&W) const { return w<W.w; } }edges[M]; int find (int x) if (p[x]!=x) p[x]=find (p[x]); return p[x]; } int kruskal () sort (edges,edges+m); for (int i=1 ;i<=n;i++) p[i]=i; int res=0 ,cnt=0 ; for (int i=0 ;i<m;i++) { int a=edges[i].a,b=edges[i].b,w=edges[i].w; a=find (a),b=find (b); if (a!=b) { p[a]=b; res+=w; cnt++; } } if (cnt<n-1 ) return INF; return res; } int main () scanf ("%d%d" ,&n,&m); for (int i=0 ;i<m;i++) { int a,b,w; scanf ("%d%d%d" ,&a,&b,&w); edges[i]={a,b,w}; } int t=kruskal (); if (t==INF) puts ("impossible" ); else printf ("%d\n" ,t); return 0 ; }
染色法判定二分图 一个图是二分图,当前仅当图中不含奇数环(由于图中不含奇数环,所以染色过程一定没有矛盾)
二分图指图能分为两个集合,每个集合内部没有边,边都在集合之间(用两种颜色染色)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <iostream> #include <cstring> #include <algorithm> using namespace std;const int N=100010 ,M=200010 ;int n,m;int h[N],e[M],ne[M],idx;int colour[N];void add (int a,int b) e[idx]=b,ne[idx]=h[a],h[a]=idx++; } bool dfs (int u,int c) colour[u]=c; for (int i=h[u];i!=-1 ;i=ne[i]) { int j=e[i]; if (!colour[j]) { if (!dfs (j,3 -c)) return false ; } else if (colour[j]==c) return false ; } return true ; } int main () scanf ("%d%d" ,&n,&m); int a,b; memset (h,-1 ,sizeof h); for (int i=1 ;i<=m;i++) { scanf ("%d%d" ,&a,&b); add (a,b),add (b,a); } bool flag=true ; for (int i=1 ;i<=n;i++) { if (!colour[i]) { if (!dfs (i,1 )) { flag=false ; break ; } } } if (flag) puts ("Yes" ); else puts ("No" ); return 0 ; }
匈牙利算法 二分图的最大匹配 姑娘 j 遇到新的追求者的心理活动:如果原来的男朋友有备胎,我就绿他,如果没有,那我看他太可怜了,就一直跟他在一起吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <cstring> #include <iostream> using namespace std;const int N=510 ,M=100010 ;int n1,n2,m;int h[N],e[M],ne[M],idx;int match[N];bool st[N];void add (int a,int b) e[idx]=b,ne[idx]=h[a],h[a]=idx++; } bool find (int x) for (int i=h[x];i!=-1 ;i=ne[i]) { int j=e[i]; if (!st[j]) { st[j]=true ; if (match[j]==0 ||find (match[j])) { match[j]=x; return true ; } } } return false ; } int main () scanf ("%d%d%d" ,&n1,&n2,&m); memset (h,-1 ,sizeof h); while (m--) { int a,b; scanf ("%d%d" ,&a,&b); add (a,b); } int res=0 ; for (int i=1 ;i<=n1;i++) { memset (st,false ,sizeof st); if (find (i)) res++; } printf ("%d\n" ,res); return 0 ; }
数论
数论
组合计数
高斯消元
简单博弈论
质数 定义:在大于1的整数中,如果值包含1和本身这两个约数,就被称之为质数,或者叫素数
所有小于等于1的数既不是质数也不是合数
(1)质数的判定——试除法
(2)分解质因数——试除法:从小到达枚举所有数,
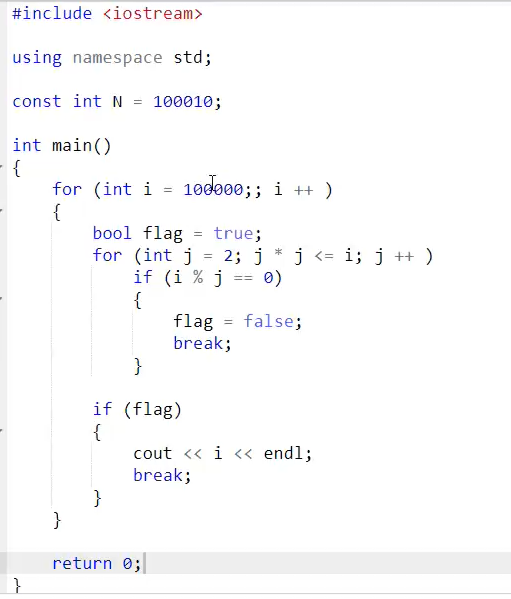
试除法判定质数 只枚举较小的约数以减小时间复杂度,时间复杂度$O(sqrt(n))$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <iostream> using namespace std;bool is_prime (int x) if (x<2 ) return false ; for (int i=2 ;i<=x/i;i++) { if (x%i==0 ) return false ; } return true ; } int main () int n; cin>>n; int m; while (n--) { cin>>m; if (is_prime (m)) puts ("Yes" ); else puts ("No" ); } return 0 ; }
分解质因子 质因数是指,能够被n 整除(也就是他的约数或者叫因子),并且本身是质数的数。
我们可以从前往后去筛,而不需要判断这个数是否是质数,举个例子n=12,那么2到12之间一共有2,3,4,5,6,7,8,9,10,11 这几个数,当i=2时,会筛掉2,4,6这几个数(前提是这几个数是ta的约数),4这个合数就是 2*2 被筛掉了 ,6同理,也就是合数等于质数和质数的乘积,不用担心该因子不是质数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> using namespace std;int divide (int x) for (int i=2 ;i<=n;i++) { if (n%i==0 ) { int s=0 ; while (n%i==0 ) { n/=i; s++; } printf ("%d %d\n" ,i,s); } } }
n中至多只包含一个大于sqrt(n)的质因子,故可以先枚举小于sqrt(n)的质因子,然后单独考虑那个大于sqrt(n)的质因子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <iostream> using namespace std;void divide (int x) for (int i=2 ;i<=x/i;i++) { if (x%i==0 ) { int s=0 ; while (x%i==0 ) x/=i,s++; cout<<i<<' ' <<s<<endl; } } if (x>1 ) cout<<x<<' ' <<1 <<endl; puts ("" ); } int main () int n,m; cin>>n; while (n--) { cin>>m; divide (m); } return 0 ; }
筛质数 埃式筛法:当一个数是质数时 (因为合数等价于用其质因子筛,对于合数我们可以直接跳过),即未被筛,则加入,同时用他向后筛他的倍数,可以想象,以他为因数的合数会被筛掉,如果后面的某个数未被筛,说明他前面的数都不是他的因数,满足质数定义,故有效。埃氏筛法复杂度差不多n,但是还是比n大一点
线性筛法:复杂度就是n
埃式筛法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> #include <algorithm> using namespace std;const int N=1000010 ;int primes[N],cnt;bool st[N];void get_primes (int n) for (int i=2 ;i<=n;i++) { if (st[i]) continue ; primes[cnt++]=i; for (int j=i+i;j<=n;j+=i) { st[j]=true ; } } } int main () int n; cin>>n; get_primes (n); cout<<cnt<<endl; return 0 ; }
线性筛法:
线性筛法的原理:n只会被最小质因子筛掉
本来我们应该对每个质数像埃氏筛法一样去筛,去把他的所有倍数找出来,但我们也可以不这样,可以并行地做,让相同的i乘以primes[j]来筛,但是是否需要让i乘以每个primes[j]来筛呢,如果i%primes[j]成立,说明primesj是i的最小质因子,我们希望每个数都被其最小质因子筛,所以i*primes[j+1]筛掉这个任务应该交给k*primes[j]来完成,同理接下来的i*primes[j+x]…,所以就不需要再循环下去了,break
那一上来把primes[j]i筛了合适吗,这个是能保证最小筛吗,如果j大于0,也就是不是第一次循环,假设现在是c+1次循环,那么在第c次判断的时候通过判断可知i%primes[c]!=0,故可知i的最小质因数大于primes[c],数i\ primes[c+1]的最小质因数要么是i要么是primes[c+1],如果是第一次循环,那么primes[j]为2,其为最小的质数,用其筛掉的数一定能保证原则用最小质因数筛
我们筛的时候总是用最小质因数来筛,并且筛的是i*primes[j],这个数筛的时候是归为用primes[j]作为最小质因数来筛的 ,因为如果归为i,i如果是合数的话,那么应该由i的最小质因数来筛,如果是质数的话,那么i刚刚加入primes数组中,按照顺序(i这个质数)(primes这个质数),显然primes这个质数更小,所以也是归为primes这个质数来筛的,所以i\ primes[j]来筛总是归为primes[j]作为最小质因数来筛所以当不满足这个条件的时候,也就是i*primes[j]不能归为primes[j]时,那么一定是i为合数,即由i的最小质因子来筛,因为如果是质数的话按照上一条,仍然归结为primes[j],也就是说i的最小质因子小于等于primes[j]吧,所以我们为了满足黑体加粗的规则,在等于的时候就跳出循环
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void get_primes (int n) for (int i = 2 ; i <= n; i ++ ) { if (!st[i]) primes[cnt ++ ] = i; for (int j = 0 ; primes[j] <= n / i; j ++ ) { st[primes[j] * i] = true ; if (i % primes[j] == 0 ) break ; } } }
约数 (1)试除法求一个数的所有约数 只需要枚举较小的约束,较大的那个可以直接计算出来
(2)约束个数 int范围内约数最多的是1500左右
(3)约束之和
约束之和展开即可呀,每个括号里选一个就行了~
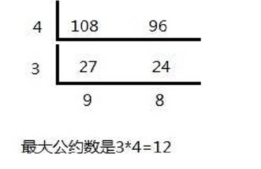
(4)最大公约数 欧几里得算法(辗转相除法)
约束个数 先把每个数分解为质因子表达式,然后用上面的公式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <iostream> #include <algorithm> #include <unordered_map> #include <vector> using namespace std;typedef long long LL;const int N=110 ,mode=1e9 +7 ;int main () int n; cin>>n; unordered_map<int ,int >primes; while (n--) { int x; cin>>x; for (int i=2 ;i<=x/i;i++) { while (x%i==0 ){ x/=i; primes[i]++; } } if (x>1 ) primes[x]++; } LL res=1 ; for (auto p:primes) res=res*(p.second+1 )%mode; cout<<res<<endl; return 0 ; }
约束之和 主要是$1+P+P^2…$的处理采用t=t*p+1的方式完成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <iostream> #include <algorithm> #include <unordered_map> #include <vector> using namespace std;typedef long long LL;const int N = 110 , mod = 1e9 + 7 ;int main () int n; cin >> n; unordered_map<int , int > primes; while (n -- ) { int x; cin >> x; for (int i = 2 ; i <= x / i; i ++ ) while (x % i == 0 ) { x /= i; primes[i] ++ ; } if (x > 1 ) primes[x] ++ ; } LL res = 1 ; for (auto p : primes) { LL a = p.first, b = p.second; LL t = 1 ; while (b -- ) t = (t * a + 1 ) % mod; res = res * t % mod; } cout << res << endl; return 0 ; }
试除法求约数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <iostream> #include <vector> #include <algorithm> using namespace std;vector<int > get_divisors (int x) vector<int > res; for (int i=1 ;i<=x/i;i++) { if (x%i==0 ) { res.push_back (i); if (i!=x/i) res.push_back (x/i); } } sort (res.begin (),res.end ()); return res; } int main () int n; cin>>n; while (n--) { int x; cin>>x; auto res=get_divisors (x); for (auto x:res) cout<<x<<" " ; cout<<endl; } return 0 ; }
最大公约数
欧几里得算法,时间复杂度$log(n)$
注意: d|a的含义是a能被d整除,即a/d
基于如下原理:d|a,d|b,则有d|ax+by,所以a和b的最大公约数(a,b)也可以表示为(b,a-c*b),可知假设(a,b)值为k,k一定都整除b和a-c*b,特殊的,这里的c取[a/b],故有(a,b)=(b,a%b),如果b为0,则由于0可以被任何数整除,0/k=0,所以最大公约数返回a(也就是说任何的数都是0的约数)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> using namespace std;int gcd (int a,int b) return b?gcd (b,a%b):a; } int main () int n; cin>>n; while (n--) { int a,b; cin>>a>>b; cout<<gcd (a,b)<<endl; } return 0 ; }
欧拉函数 欧拉函数 互质:公约数只有1的两个整数
欧拉函数就是求出1~N中与N互质的数的个数,比如6与1,5互质,故欧拉函数值为2
欧拉公式原理:上面的公式展开就是下面的容斥原理,比如1/p1这个项前面是负号,两个的话是正号。。。。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> using namespace std;int phi (int x) int res=x; for (int i=2 ;i<=x/i;i++) { if (x%i==0 ) { res=res/i*(i-1 ); while (x%i==0 ) x/=i; } } if (x>1 ) res=res/x*(x-1 ); return res; } int main () int n; cin>>n; while (n--) { int x; cin>>x; cout<<phi (x)<<endl; } return 0 ; }
筛法求欧拉函数 如果要求1~N中每一个数的欧拉函数,如果用公式来算,分解质因数n次将复杂度变成$O(n*sqrt(n))$,而筛法求每个数的欧拉函数的时间复杂度为$O(n)$
在线性筛法的过程中顺便把欧拉函数求出来,注意欧拉函数的定义,1~N中与N互质的数的个数
若i是质数,那么i与前i-1个数均互质,这是质数的定义(质数只有他自己和1两个因子),故其phi值为i-1
primes[j]*i的phi值
如果i%primes[j]==0,按照线性筛法,此时primes[j]恰好是i的最小质因数,所以按照公式可知:phi[i%primes[j]]=primes[j]*phi[i]
如果i%primes[j]!=0,按照线性筛法,此时i的最小质因子大于primes,故需要分别计算i和primes[j]的质因子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <iostream> using namespace std;typedef long long LL;const int N=1000010 ;int primes[N],cnt;int euler[N];bool st[N];void get_euler (int n) euler[1 ]=1 ; for (int i=2 ;i<=n;i++) { if (!st[i]) { primes[cnt++]=i; euler[i]=i-1 ; } for (int j=0 ;primes[j]<=n/i;j++) { int t=primes[j]*i; st[t]=true ; if (i%primes[j]==0 ) { euler[t]=euler[i]*primes[j]; break ; } euler[t]=euler[i]*(primes[j]-1 ); } } } int main () int n; cin>>n; get_euler (n); LL res=0 ; for (int i=1 ;i<=n;i++) res+=euler[i]; cout<<res<<endl; return 0 ; }
欧拉函数的一个运用,因为a和n互质,假设1~n中与n互质的数为a1,a2,…a_phi(n),将这些数乘以a后也将与n互质(只有1这一个公因子),而在模n的情况下这两种应该是等价的(模n之后),所以乘起来,可得上面的公式,如5^2^=25%6=1,其中phi(6)=2
快速幂 原理:
例子:
快速幂 若求A的B次方的后几位数,则这里的后几位数就是q
LL res = 1 % p;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <iostream> using namespace std;typedef long long LL;LL qmi (int a,int b,int q) LL res=1 %q; while (b) { if (b&1 ) res=res*a%q; a=a*(LL)a%q; b>>=1 ; } return res%q; } int main () int n; scanf ("%d" ,&n); while (n--) { int a,b,q; scanf ("%d%d%d" ,&a,&b,&q); printf ("%lld\n" ,qmi (a,b,q)); } return 0 ; }
快速幂求逆元 在欧几里得算法那节我们知道了费马定理:注意条件是a和p互质且p是质数 ,如果a是p的倍数,快速幂是无法求的
b的逆元就是上面的x,最终通过费马定理转换为求b^(n-2)%n,转变为快速幂
注意这里a和n要求互质,否则结果是impossible
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <iostream> using namespace std;typedef long long LL;LL qmi (int a,int b,int p) LL res=1 ; while (b) { if (b&1 ) res=res*a%p; a=a*(LL)a%p; b>>=1 ; } return res; } int main () int n; cin>>n; int a,p; while (n--) { scanf ("%d%d" ,&a,&p); if (a%p==0 ) puts ("impossible" ); else printf ("%lld\n" ,qmi (a,p-2 ,p)); } return 0 ; }
扩展欧几里得算法 欧几里得算法:
基于如下原理:d|a,d|b,则有d|ax+by,所以a和b的最大公约数(a,b)也可以表示为(b,a-c*b),可知假设(a,b)值为k,k一定都整除b和a-c*b,特殊的,这里的c取[a/b],故有(a,b)=(b,a%b),如果b为0,则由于0可以被任何数整除,0/k=0,所以最大公约数返回a(也就是说任何的数都是0的约数)
裴蜀定理:对于任意正整数a,b,一定存在非零整数x,y,使得ax+by=(a,b)的最大公约数
最大公约数就是最大公因数,扩展欧几里得就是构造x和y,利用的是递归的思想
当b为0时,可以轻易写出来,当b不为0时,找到前后两层的递归关系
扩展欧几里得算法
x、y并不唯一,算法求出其一
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> using namespace std;int exgcd (int a,int b,int &x,int &y) if (!b) { x=1 ,y=0 ; return a; } int d=exgcd (b,a%b,y,x); y-=a/b*x; return d; } int main () int n; scanf ("%d" ,&n); int a,b; while (n--) { scanf ("%d%d" ,&a,&b); int x,y; exgcd (a,b,x,y); printf ("%d %d\n" ,x,y); } return 0 ; }
线性同余方程
根据欧几里得算法,对于ax+my=d,其中d是a和m的最大公约数,一定在一些条件下有解,但是题目给出的是b,所以不一定有解,有解的条件是b能够被d整除,并且可知实际的x值会因此而扩大b/d倍
线性同余方程求的是这个x,思路是用扩展欧几里得首先求a和m的最大公约数d,然后把求得的x扩展b/d倍
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> using namespace std;typedef long long LL;int exgcd (int a,int b,int &x,int &y) if (!b) { x=1 ,y=0 ; return a; } int t=exgcd (b,a%b,y,x); y-=a/b*x; return t; } int main () int n; scanf ("%d" ,&n); int a,b,m; while (n--) { scanf ("%d%d%d" ,&a,&b,&m); int x,y; int d=exgcd (a,m,x,y); if (b%d) puts ("impossible" ); else printf ("%d\n" ,(LL)b/d*x%m); } return 0 ; }
假设某个特解为ax0+by0=n;
中国剩余定理 表达整数的奇怪方式
按照上图的步骤来求:
首先化为k1a1-k2a2=m2-m1形式,这个形式做两件事情,第一件事情是判断是否有解,有解等价于(m2-m1)是(a1,a2)的倍数,第二件事情是根据扩展欧几里得算法求出k1
但是为了题目的x的最小条件,我们需要根据扩展欧几里得的通解形式缩小k1,这也是一步
在求出k1之后我们就可以求x了,x=a1k1+m1+
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> #include <algorithm> using namespace std;typedef long long LL;LL exgcd (LL a,LL b,LL &x,LL &y) { if (!b){ x=1 ,y=0 ; return a; } LL d=exgcd (b,a%b,y,x); y-=a/b*x; return d; } int main () int n; cin>>n; LL x=0 ,m1,a1; cin>>a1>>m1; for (int i=0 ;i<n-1 ;i++){ LL m2,a2; cin>>a2>>m2; LL k1,k2; LL d=exgcd (a1,a2,k1,k2); if ((m2-m1)%d){ x=-1 ; break ; } k1*=(m2-m1)/d; LL t=a2/d; k1=(k1%t+t)%t; x=k1*a1+m1; m1=k1*a1+m1; a1=abs (a1/d*a2); } if (x!=-1 ) x=(m1%a1+a1)%a1; cout<<x<<endl; return 0 ; }
高斯消元 高斯消元解线性方程组
线性方程组有三种情况的解,先将矩阵化为上三角
如果出现左侧和右侧都是0的行,说明方程组中该方程可以被其他方程表出,故方程组有无穷解
如果出现左侧全为0右侧不为0的行,则方程组无解
否则就是有唯一解,通过初等行变换,高斯消元的方法求解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 #include <iostream> #include <cstring> #include <algorithm> #include <cmath> using namespace std;const int N = 110 ;const double eps = 1e-8 ;int n;double a[N][N];int gauss () int c, r; for (c = 0 , r = 0 ; c < n; c ++ ) { int t = r; for (int i = r; i < n; i ++ ) if (fabs (a[i][c]) > fabs (a[t][c])) t = i; if (fabs (a[t][c]) < eps) continue ; for (int i = c; i <= n; i ++ ) swap (a[t][i], a[r][i]); for (int i = n; i >= c; i -- ) a[r][i] /= a[r][c]; for (int i = r + 1 ; i < n; i ++ ) if (fabs (a[i][c]) > eps) for (int j = n; j >= c; j -- ) a[i][j] -= a[r][j] * a[i][c]; r ++ ; } if (r < n) { for (int i = r; i < n; i ++ ) if (fabs (a[i][n]) > eps) return 2 ; return 1 ; } for (int i = n - 1 ; i >= 0 ; i -- ) for (int j = i + 1 ; j < n; j ++ ) a[i][n] -= a[i][j] * a[j][n]; return 0 ; } int main () scanf ("%d" , &n); for (int i = 0 ; i < n; i ++ ) for (int j = 0 ; j < n + 1 ; j ++ ) scanf ("%lf" , &a[i][j]); int t = gauss (); if (t == 2 ) puts ("No solution" ); else if (t == 1 ) puts ("Infinite group solutions" ); else { for (int i = 0 ; i < n; i ++ ) printf ("%.2lf\n" , a[i][n]); } return 0 ; }
求组合数 求组合数有多种方式,需要根据题目数据范围来选择合适的做法
求组合数有多种方式,要根据数据的范围选择
求组合数1 考虑打表的方式直接弄出来,直接预处理出来每一个数,复杂度O(n^2^)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> using namespace std;const int N=2010 ,mod=1e9 +7 ;int c[N][N];void init () for (int i=0 ;i<N;i++) { for (int j=0 ;j<=i;j++) { if (!j) c[i][j]=1 ; else c[i][j]=(c[i-1 ][j]+c[i-1 ][j-1 ])%mod; } } } int main () int n; init (); scanf ("%d" ,&n); while (n--) { int a,b; scanf ("%d%d" ,&a,&b); printf ("%d\n" ,c[a][b]); } return 0 ; }
求组合数2 预处理出来阶乘,用公式计算组合数,但是不存在除法分开取模的特征,所以要计算逆元来做,所以预处理出来一个数的阶乘和他的逆元
处理出来数的阶乘,和数的逆元的相乘结果
两个long long级别的数相乘就要mod一次了~,复杂度O(NlogN)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <iostream> using namespace std;typedef long long LL;const int N=100010 ,mod=1e9 +7 ;int fact[N],infact[N];int qmi (int a,int k,int p) int res=1 ; while (k) { if (k&1 ) res=(LL)res*a%p; a=(LL)a*a%p; k>>=1 ; } return res; } int main () fact[0 ]=infact[0 ]=1 ; for (int i=1 ;i<N;i++) { fact[i]=(LL)fact[i-1 ]*i%mod; infact[i]=(LL)infact[i-1 ]*qmi (i,mod-2 ,mod)%mod; } int n; int a,b; scanf ("%d" ,&n); while (n--) { scanf ("%d%d" ,&a,&b); printf ("%d\n" ,(LL)fact[a]*infact[b]%mod*infact[a-b]%mod); } return 0 ; }
求组合数3 采用lucus定理来做:AcWing 887. 求组合数 III - AcWing
关键的一步是来凑出b0+b1*p1+…凑出来b
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 #include <iostream> using namespace std;typedef long long LL;int qmi (int a,int k,int p) int res=1 ; while (k) { if (k&1 ) res=(LL) res*a%p; a=(LL)a*a%p; k>>=1 ; } return res; } int C (int a,int b,int p) if (b>a) return 0 ; int res=1 ; for (int i=1 ,j=a;i<=b;i++,j--) { res=(LL)res*j%p; res=(LL)res*qmi (i,p-2 ,p)%p; } return res; } int lucas (LL a,LL b,int p) if (a<p&&b<p) return C (a,b,p); return (LL)C (a%p,b%p,p)*lucas (a/p,b/p,p)%p; } int main () int n; scanf ("%d" ,&n); LL a,b; int p; while (n--) { scanf ("%lld%lld%d" ,&a,&b,&p); printf ("%d\n" ,lucas (a,b,p)); } return 0 ; }
求组合数4 要求求准确的解,而不是模一个数,可以直接用公式来计算,涉及到高精度乘法和高精度除法,效率较低
方法是先将C(a,b)分解质因数a!/((a-b)!*(b!)),然后只用高精度乘法来做即可AcWing 888. 求组合数 IV(高精度-素数组合) - AcWing
首先筛1~a之间的所有质数
再求每个质数的次数
用高精度乘法将上述质数乘上
这里计算每个质数的次数的方法如下:
以2为例:
其实代码里面更好理解,就是不断地除p
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 #include <iostream> #include <algorithm> #include <vector> using namespace std;const int N=5010 ;int primes[N],cnt;int sum[N];bool st[N];void get_primes (int n) for (int i=2 ;i<=n;i++) { if (!st[i]) primes[cnt++]=i; for (int j=0 ;primes[j]<=n/i;j++) { st[primes[j]*i]=true ; if (i%primes[j]==0 ) break ; } } } int get (int n,int p) int res=0 ; while (n) { res+=n/p; n/=p; } return res; } vector<int > mul (vector<int > a,int b) vector<int > c; int t=0 ; for (int i=0 ;i<a.size ();i++) { t+=a[i]*b; c.push_back (t%10 ); t/=10 ; } while (t) { c.push_back (t%10 ); t/=10 ; } return c; } int main () int a,b; cin>>a>>b; get_primes (a); for (int i=0 ;i<cnt;i++) { int p=primes[i]; sum[i]=get (a,p)-get (a-b,p)-get (b,p); } vector<int > res; res.push_back (1 ); for (int i=0 ;i<cnt;i++) { for (int j=0 ;j<sum[i];j++) { res=mul (res,primes[i]); } } for (int i=res.size ()-1 ;i>=0 ;i--) printf ("%d" ,res[i]); return 0 ; }
满足条件的01序列 参考:AcWing 889. 满足条件的01序列 - AcWing ,即求卡特兰数
注意快速幂求逆元的条件,要求mod为质数
问题转换为从0,0走到n,n的满足一定条件的路径,将序列中0看成向右走,1看成向上走,最终走到(n,n)位置,但是题目要求序列前缀中0的个数要不少于1的个数,所以x>=y,也就是说不能碰到红色的线,那如何求碰到红色线的路径数量呢,任何一个碰到红线然后到达(n,n)的路径通过红线进行镜像处理,最终一定会镜像到达(n-1,n+1)这个点的一条路径,所以只需要求出从(0,0)到达(n-1,n+1)这个点的路径数量,然后相减即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <iostream> #include <algorithm> using namespace std;typedef long long LL;const int N=100010 ,mod=1e9 +7 ;int qmi (int a,int k,int p) int res=1 ; while (k) { if (k&1 ) res=(LL)res*a%p; a=(LL)a*a%p; k>>=1 ; } return res; } int main () int n; cin>>n; int a=n*2 ,b=n; int res=1 ; for (int i=a;i>a-b;i--) res=(LL)res*i%mod; for (int i=1 ;i<=b;i++) res=(LL)res*qmi (i,mod-2 ,mod)%mod; res=(LL)res*qmi (n+1 ,mod-2 ,mod)%mod; cout<<res<<endl; return 0 ; }
容斥原理
实现的时候以位运算的方式实现,假设有n个数m个类别,则从1~2^m^-1进行枚举,每一位上表示该位上的集合是否取,在枚举的过程中计算上述等式
能被整除的数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #include <iostream> using namespace std;typedef long long LL;const int N=20 ;int p[N];int main () int n,m; cin>>n>>m; for (int i=0 ;i<m;i++) cin>>p[i]; int res=0 ; for (int i=1 ;i<1 <<m;i++) { int t=1 ,s=0 ; for (int j=0 ;j<m;j++) { if (i>>j&1 ) { if ((LL)t*p[j]>n) { t=-1 ; break ; } t*=p[j]; s++; } } if (t!=-1 ) { if (s%2 ) res+=n/t; else res-=n/t; } } cout<<res; return 0 ; }
博弈论 若一个游戏满足:
由两名玩家交替行动公平组合游戏 。
尼姆游戏(NIM)属于公平组合游戏,但常见的棋类游戏,比如围棋就不是公平组合游戏,因为围棋交战双方分别只能落黑子和白子,胜负判定也比较负责,不满足条件2和3。
Nim游戏 ai是每堆中数量
先手必胜状态:先手操作完,可以走到某一个必败状态(给对方留下必败状态)
证明:
对于先手,如果遇到全0的局面,则败
如果先手遇到异或不为0的情况,假设异或结果为x,假设x的最高位1所在位为k,则至少存在ai第k位为1,ai异或x<ai,所以在取的过程中可以将ai取为(ai异或x)的状态,因为x是a1~an的异或,将ai取完之后一定能将异或结果转为0,后手必败,先手必胜
如果先手遇到异或为0的情况,则无论怎么取,异或结果都不是0.也就是对手必胜态,反证法:假设取完后异或结果为0,取的项ai变成了ai’,则将前后两次项进行异或:a1\^a2…\^ai\^an ^ a1\^a2\^…\^ai‘\^an=ai\^ai’,如果是0,则ai=ai’,则不满足取这一动作,故不可能为0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <iostream> using namespace std;const int N=1e5 +10 ;int main () int n,tmp,x=0 ; scanf ("%d" ,&n); while (n--) { scanf ("%d" ,&tmp); x^=tmp; } if (x) puts ("Yes" ); else puts ("No" ); return 0 ; }
台阶-Nim游戏 如果先手时奇数台阶上的值的异或值为0,则先手必败,反之必胜
注意判断奇数的处理:i&1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <iostream> #include <algorithm> using namespace std;const int N=1e5 +10 ;int main () int n; scanf ("%d" ,&n); int res=0 ; for (int i=1 ;i<=n;i++) { int x; scanf ("%d" ,&x); if (i&1 ) res^=x; } if (res) puts ("Yes" ); else puts ("No" ); return 0 ; }
集合-Nim游戏 AcWing 893. 集合-Nim游戏 - AcWing
用到了sg数组,sg数组通过mex函数定义,sg=mex{sg(后继)},即在后继中未出现的最小的非负整数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <iostream> #include <unordered_set> #include <cstring> using namespace std;const int N=110 ,M=10010 ;int n,m;int s[N],f[M];int sg (int x) if (f[x]!=-1 ) return f[x]; unordered_set<int > S; for (int i=0 ;i<n;i++) { int sum=s[i]; if (x>=sum) S.insert (sg (x-sum)); } for (int i=0 ;;i++) { if (!S.count (i)) return f[x]=i; } } int main () scanf ("%d" ,&n); for (int i=0 ;i<n;i++) scanf ("%d" ,&s[i]); scanf ("%d" ,&m); memset (f,-1 ,sizeof f); int res=0 ; for (int i=0 ;i<m;i++) { int x; scanf ("%d" ,&x); res^=sg (x); } if (res) puts ("Yes" ); else puts ("No" ); return 0 ; }
拆分-Nim游戏 sg(b1,b2)=sg(b1)$\and$sg(b2)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <iostream> #include <cstring> #include <unordered_set> using namespace std;const int N=110 ;int n;int f[N];int sg (int x) if (f[x]!=-1 ) return f[x]; unordered_set<int > set; for (int i=0 ;i<x;i++) { for (int j=0 ;j<x;j++) { set.insert (sg (i)^sg (j)); } } for (int i=0 ;;i++) { if (!set.count (i)) { return f[x]=i; } } } int main () scanf ("%d" ,&n); memset (f,-1 ,sizeof f); int res=0 ; while (n--) { int x; cin>>x; res^=sg (x); } if (res) puts ("Yes" ); else puts ("No" ); return 0 ; }
动态规划
DP需要注意初始化——from xiao
背包问题 0-1背包问题:每件物品最多使用一次
完全背包问题:每件物品有无限个
多重背包问题:每件物品有s[i]个,有一种优化计算方式
分组背包问题:有多个组,每组里只能选一个
优化和变形都是在原方程基础上进行的等价变形,降维的时候如果用到的是上一层的状态,就要逆序枚举,如果用到的是本层的状态,就要顺序枚举
0-1背包问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> using namespace std;const int N=1010 ;int V[N],W[N];int n,v;int dp[N][N];int main () cin>>n>>v; for (int i=1 ;i<=n;i++) { cin>>V[i]>>W[i]; } for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=v;j++) { if (j>=V[i]) dp[i][j]=max (dp[i-1 ][j],dp[i-1 ][j-V[i]]+W[i]); else dp[i][j]=dp[i-1 ][j]; } } cout<<dp[n][v]; return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def main (): n,m = map (int ,input ().split()) V = [0 ]*(n+1 ) W = [0 ]*(n+1 ) dp = [[0 ]*(m+1 ) for _ in range (n+1 )] for i in range (1 ,n+1 ): V[i],W[i] = map (int ,input ().split()) for i in range (1 ,n+1 ): for j in range (1 ,m+1 ): if j>=V[i]: dp[i][j] = max (dp[i-1 ][j],dp[i-1 ][j-V[i]]+W[i]) else : dp[i][j] = dp[i-1 ][j] print (dp[n][m]) main()
降维后
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <iostream> using namespace std;const int N=1010 ;int V[N],W[N];int n,v;int dp[N];int main () cin>>n>>v; for (int i=1 ;i<=n;i++) { cin>>V[i]>>W[i]; } for (int i=1 ;i<=n;i++) { for (int j=v;j>=V[i];j--) { dp[j]=max (dp[j],dp[j-V[i]]+W[i]); } } cout<<dp[v]; return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 def main (): n,m = map (int ,input ().split()) V = [0 ]*(n+1 ) W = [0 ]*(n+1 ) dp = [0 ]*(m+1 ) for i in range (1 ,n+1 ): V[i],W[i] = map (int ,input ().split()) for i in range (1 ,n+1 ): for j in range (m,0 ,-1 ): if j>=V[i]: dp[j] = max (dp[j],dp[j-V[i]]+W[i]) print (dp[m]) main()
完全背包问题 每个物品无数个
朴素做法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <iostream> using namespace std;const int N=1010 ;int dp[N][N];int n,c;int w[N],v[N];int main () cin>>n>>c; for (int i=1 ;i<=n;i++) { cin>>w[i]>>v[i]; } for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=c;j++) { dp[i][j]=dp[i-1 ][j]; for (int k=1 ;k*w[i]<=j;k++) { dp[i][j]=max (dp[i][j],dp[i-1 ][j-k*w[i]]+k*v[i]); } } } cout<<dp[n][c]; return 0 ; }
优化做法:替换公式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> using namespace std;const int N=1010 ;int dp[N][N];int n,c;int w[N],v[N];int main () cin>>n>>c; for (int i=1 ;i<=n;i++) { cin>>w[i]>>v[i]; } for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=c;j++) { dp[i][j]=dp[i-1 ][j]; if (j>=w[i]) dp[i][j]=max (dp[i][j],dp[i][j-w[i]]+v[i]); } } cout<<dp[n][c]; return 0 ; }
终极优化:替换公式+降维 ,注意是顺序的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <iostream> #include <algorithm> using namespace std;const int N=1010 ;int f[N];int n,m;int main () cin>>n>>m; int v,w; for (int i=1 ;i<=n;i++) { cin>>v>>w; for (int j=v;j<=m;j++) { f[j]=max (f[j],f[j-v]+w); } } cout<<f[m]<<endl; return 0 ; }
python
1 2 3 4 5 6 7 8 9 10 11 12 13 def main (): n,m = map (int ,input ().split()) V = [0 ]*(n+1 ) W = [0 ]*(n+1 ) dp = [0 ]*(m+1 ) for i in range (1 ,n+1 ): V[i],W[i] = map (int ,input ().split()) for i in range (1 ,n+1 ): for j in range (1 ,m+1 ): if j>=V[i]: dp[j] = max (dp[j],dp[j-V[i]]+W[i]) print (dp[m]) main()
多重背包问题 每个物品有限个,具体有s[i]个
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> using namespace std;const int N=110 ;int n,v;int V[N],S[N],W[N];int dp[N][N];int main () cin>>n>>v; for (int i=1 ;i<=n;i++) { cin>>V[i]>>W[i]>>S[i]; } for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=v;j++) { for (int k=0 ;k<=S[i]&&j>=k*V[i];k++) { dp[i][j]=max (dp[i][j],dp[i-1 ][j-k*V[i]]+k*W[i]); } } } cout<<dp[n][v]; return 0 ; }
二进制优化
优化的思想:将第i组可拿的s[i]个物品进行拆分,按照二进制进行打包成一个物品,只需要对拆分后的$log(s)$个物品进行选或者不选,就能等效于对s[i]个物品选的数量,具体将s[i]个物品拆分成: 1 , 2 , 4 , 2^k^ , c ,其中1+2+4+…+2^k^<=s[i],但k+1次方不满足该条件,c是s[i]-(1+2+4+…+2^k^)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <iostream> using namespace std;const int N=20000 ,M=2010 ;int V[N],W[N];int n,v;int f[M];int main () cin>>n>>v; int a,b,s; int cnt=0 ; for (int i=1 ;i<=n;i++) { cin>>a>>b>>s; int k=1 ; while (k<=s) { cnt++; V[cnt]=a*k; W[cnt]=b*k; s=s-k; k=k*2 ; } if (s>0 ) { cnt++; V[cnt]=s*a; W[cnt]=s*b; } } n=cnt; for (int i=1 ;i<=n;i++) { for (int j=v;j>=V[i];j--) { f[j]=max (f[j],f[j-V[i]]+W[i]); } } cout<<f[v]; }
分组背包问题 分成多个组,每组之中只能选0个或者1个
二维dp:
降维优化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> using namespace std;const int N=110 ;int n,m;int v[N][N],w[N][N],s[N];int f[N];int main () cin>>n>>m; for (int i=1 ;i<=n;i++) { cin>>s[i]; for (int j=1 ;j<=s[i];j++) { cin>>v[i][j]>>w[i][j]; } } for (int i=1 ;i<=n;i++) { for (int j=m;j>=0 ;j--) { for (int k=1 ;k<=s[i];k++) { if (v[i][k]<=j) { f[j] = max (f[j], f[j - v[i][k]] + w[i][k]); } } } } cout<<f[m]; return 0 ; }
线性DP 线性指递推有个模糊的顺序,如背包问题的二维表从左到右
数字三角形
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> #include <algorithm> using namespace std;const int N = 510 , INF = 1e9 ;int n;int a[N][N];int f[N][N];int main () scanf ("%d" , &n); for (int i = 1 ; i <= n; i ++ ) for (int j = 1 ; j <= i; j ++ ) scanf ("%d" , &a[i][j]); for (int i = 0 ; i <= n; i ++ ) for (int j = 0 ; j <= i + 1 ; j ++ ) f[i][j] = -INF; f[1 ][1 ] = a[1 ][1 ]; for (int i = 2 ; i <= n; i ++ ) for (int j = 1 ; j <= i; j ++ ) f[i][j] = max (f[i - 1 ][j - 1 ] + a[i][j], f[i - 1 ][j] + a[i][j]); int res = -INF; for (int i = 1 ; i <= n; i ++ ) res = max (res, f[n][i]); printf ("%d\n" , res); return 0 ; }
最长上升子序列一
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <iostream> using namespace std;const int N=1010 ;int n;int a[N];int f[N];int main () scanf ("%d" ,&n); for (int i=1 ;i<=n;i++) { scanf ("%d" ,&a[i]); f[i]=1 ; } for (int i=2 ;i<=n;i++) { for (int j=1 ;j<i;j++) { if (a[j]<a[i]) { f[i]=max (f[i],f[j]+1 ); } } } int res=0 ; for (int i=1 ;i<=n;i++) { res=max (res,f[i]); } cout<<res; return 0 ; }
最长上升子序列贰 采用类似单调队列的样子,s[i]存储长度为i的最长上升子序列的最小的末尾元素,可证明s存储的结果一定是严格单调递增的,证明:
假设s[i]=s[i+1],则可知对于长度为i+1的子序列,其最小的末尾元素是s[i+1],那这个序列的第i个元素一定小于s[i+1],与s[i]=s[i+1]不符,故可证;若s[i]>s[i+1],同理可证
所以s数组一定是单调递增的,当插入一个新的数h时,先找到最大的比h小的数s[k],可知由于s[k]是长度为k的子序列中末尾元素最小的,所以h与该序列拼接可以得到一个长度为k+1的子序列,所以我们需要将其与s[k+1]的大小进行比较,判断是否能替换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> using namespace std;const int N=1e5 +10 ;int n;int a[N],f[N];int cnt;int find (int x) int l=1 ,r=cnt; while (l<r) { int mid=l+r>>1 ; if (f[mid]>=x) r=mid; else l=mid+1 ; } return l; } int main () cin>>n; for (int i=1 ;i<=n;i++) cin>>a[i]; f[++cnt]=a[1 ]; for (int i=2 ;i<=n;i++) { if (a[i]>f[cnt]) f[++cnt]=a[i]; else { int idx=find (a[i]); f[idx]=a[i]; } } cout<<cnt; return 0 ; }
最长公共子序列 书上的解释是:
注意这里的f[i-1,j]是包含01和00的,而不是准确表示出第j个一定选,也就是说f[i-1,j]项与f[i-1,j-1]重叠,但由于求的是max,所以不要求不重复,由于f[i-1,j]和f[i,j-1]包含了f[i-1,j-1],所以无需再比较f[i-1,j-1]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> using namespace std;const int N=1010 ;int n,m;char a[N];char b[N];int f[N][N];int main () scanf ("%d%d" ,&n,&m); scanf ("%s" ,a+1 ); scanf ("%s" ,b+1 ); for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=m;j++) { f[i][j]=max (f[i-1 ][j],f[i][j-1 ]); if (a[i]==b[j]) { f[i][j]=max (f[i][j],f[i-1 ][j-1 ]+1 ); } } } cout<<f[n][m]; return 0 ; }
编辑距离
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> using namespace std;const int N=1010 ;int n,m;char a[N],b[N];int dp[N][N];int main () cin>>n>>a+1 ; cin>>m>>b+1 ; for (int i=1 ;i<=n;i++) dp[i][0 ]=i; for (int j=1 ;j<=m;j++) dp[0 ][j]=j; for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=m;j++) { dp[i][j]=min (dp[i-1 ][j]+1 ,dp[i][j-1 ]+1 ); if (a[i]==b[j]) dp[i][j]=min (dp[i][j],dp[i-1 ][j-1 ]); else dp[i][j]=min (dp[i][j],dp[i-1 ][j-1 ]+1 ); } } cout<<dp[n][m]; return 0 ; }
区间DP 区间 DP 常用模版
所有的区间dp问题枚举时,第一维通常是枚举区间长度,并且一般 len = 1 时用来初始化,枚举从 len = 2 开始;第二维枚举起点 i (右端点 j 自动获得,j = i + len - 1),从小区间到大区间,以使得大区间能使用小区间的解
模板代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 for (int len = 1 ; len <= n; len++) { for (int i = 1 ; i + len - 1 <= n; i++) { int j = i + len - 1 ; if (len == 1 ) { dp[i][j] = 初始值 continue ; } for (int k = i; k < j; k++) { dp[i][j] = min (dp[i][j], dp[i][k] + dp[k + 1 ][j] + w[i][j]); } } }
如上循环模式是因为要保证计算dp[i][j]时其依赖的较小的区间的dp值已经计算得到了
石子合并
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> using namespace std;const int N=310 ;int s[N];int f[N][N];int n;int main () scanf ("%d" ,&n); for (int i=1 ;i<=n;i++) { scanf ("%d" ,&s[i]); } for (int i=1 ;i<=n;i++) s[i]+=s[i-1 ]; for (int len=2 ;len<=n;len++) { for (int i=1 ;i+len-1 <=n;i++) { int l=i,r=i+len-1 ; f[l][r]=1e8 ; for (int k=l;k<r;k++) { f[l][r]=min (f[l][r],f[l][k]+f[k+1 ][r]+s[r]-s[l-1 ]); } } } cout<<f[1 ][n]; return 0 ; }
计数类DP 整数划分问题 方法一
转换为完全背包问题,f[i][j]表示用前i个数凑出j的方案数,易知根据最后一个数的多少进行划分计算最后求和
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #include <iostream> using namespace std;const int N=1010 ,mod=1e9 +7 ;int n;int f[N][N];int main () cin>>n; for (int i=0 ;i<=n;i++) f[i][0 ]=1 ; for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=n;j++) { f[i][j]=f[i-1 ][j]; for (int k=1 ;k*i<=j;k++) { f[i][j]=(f[i][j]+f[i-1 ][j-k*i])%mod; } } } cout<<f[n][n]; return 0 ; }
利用一下变形
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> using namespace std;const int N = 1e3 + 7 , mod = 1e9 + 7 ;int f[N][N];int main () int n; cin >> n; for (int i = 0 ; i <= n; i ++) { f[i][0 ] = 1 ; } for (int i = 1 ; i <= n; i ++) { for (int j = 0 ; j <= n; j ++) { f[i][j] = f[i - 1 ][j] % mod; if (j >= i) f[i][j] = (f[i - 1 ][j] + f[i][j - i]) % mod; } } cout << f[n][n] << endl; }
降维——最终写法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <iostream> using namespace std;const int N=1010 ,mod=1e9 +7 ;int n;int dp[N];int main () cin>>n; dp[0 ]=1 ; for (int i=1 ;i<=n;i++) { for (int j=i;j<=n;j++) { dp[j]=(dp[j]+dp[j-i])%mod; } } cout<<dp[n]; return 0 ; }
方法二
状态表示:
状态转移方程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> #include <algorithm> using namespace std;const int N = 1010 , mod = 1e9 + 7 ;int n;int f[N][N];int main () cin >> n; f[1 ][1 ] = 1 ; for (int i = 2 ; i <= n; i ++ ) for (int j = 1 ; j <= i; j ++ ) f[i][j] = (f[i - 1 ][j - 1 ] + f[i - j][j]) % mod; int res = 0 ; for (int i = 1 ; i <= n; i ++ ) res = (res + f[n][i]) % mod; cout << res << endl; return 0 ; }
数位统计DP 计数问题 分情况讨论
问题转换为求1~n这些数中数字i出现的次数,假设n一共有7位,如abcdefg,现在我们考虑第4位(d)上数字i出现的次数,我们构造的数为xxxiyyy
若d不为0,xxx取000~abc-1,yyy对于每种xxx的取法都可以取000~999,故为abc*1000
若d为0,则xxx不能取000,因为000 0 123写做123,实际上不会写出这个0,所以这里xxx只能取001~abc-1,yyy取000~999,故为(abc-1)*1000
若XXX取abc,此时若d>i,则yyy可取000~999,故为1000
若XXX取abc,此时若d=i,则yyy可取000~efg,故为efg+1,若d<i不能取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 # include <iostream> # include <cmath> using namespace std;int dgt (int n) int res = 0 ; while (n) ++ res, n /= 10 ; return res; } int cnt (int n, int i) int res = 0 , d = dgt (n); for (int j = 1 ; j <= d; ++ j) { int p = pow (10 , j - 1 ), l = n / p / 10 , r = n % p, dj = n / p % 10 ; if (i) res += l * p; else if (!i && l) res += (l - 1 ) * p; if ( (dj > i) && (i || l) ) res += p; if ( (dj == i) && (i || l) ) res += r + 1 ; } return res; } int main () int a, b; while (cin >> a >> b , a) { if (a > b) swap (a, b); for (int i = 0 ; i <= 9 ; ++ i) cout << cnt (b, i) - cnt (a - 1 , i) << ' ' ; cout << endl; } return 0 ; }
状态压缩DP 蒙德里安的梦想
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 #include <bits/stdc++.h> using namespace std;const int N = 12 , M = 1 << N; long long f[N][M] ;bool st[M]; vector<vector<int >> state (M); int m, n;int main () while (cin >> n >> m, n || m) { for (int i = 0 ; i < (1 << n); i ++) { int cnt = 0 ; bool isValid = true ; for (int j = 0 ; j < n; j ++) { if ( (i >> j) & 1 ) { if (cnt & 1 ) { isValid =false ; break ; } cnt = 0 ; } else cnt ++; } if (cnt & 1 ) isValid = false ; st[i] = isValid; } for (int j = 0 ; j < (1 << n); j ++) { state[j].clear (); for (int k = 0 ; k < (1 << n); k ++) { if ((j & k ) == 0 && st[ j | k]) state[j].push_back (k); } } memset (f, 0 , sizeof f); f[0 ][0 ] = 1 ; for (int i = 1 ; i <= m; i ++) { for (int j = 0 ; j < (1 <<n); j ++) { for (auto k : state[j]) f[i][j] += f[i-1 ][k]; } } cout << f[m][0 ] << endl; } }
最短Hamilton路径
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> #include <cstring> #include <algorithm> using namespace std;const int N=20 ,M=1 <<N;int f[M][N],w[N][N];int main () int n; cin>>n; for (int i=0 ;i<n;i++) for (int j=0 ;j<n;j++) cin>>w[i][j]; memset (f,0x3f ,sizeof (f)); f[1 ][0 ]=0 ; for (int i=0 ;i<1 <<n;i++) for (int j=0 ;j<n;j++) if (i>>j&1 ) for (int k=0 ;k<n;k++) if (i>>k&1 ) f[i][j]=min (f[i][j],f[i-(1 <<j)][k]+w[k][j]); cout<<f[(1 <<n)-1 ][n-1 ]<<endl; return 0 ; }
记忆化搜索 滑雪
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <iostream> #include <cstring> #include <algorithm> using namespace std;const int N=310 ;int n,m;int h[N][N];int f[N][N];int dx[4 ]={-1 ,0 ,1 ,0 },dy[4 ]={0 ,1 ,0 ,-1 };int dp (int x,int y) if (f[x][y]!=-1 ) return f[x][y]; f[x][y]=1 ; for (int i=0 ;i<4 ;i++) { int a=x+dx[i],b=y+dy[i]; if (a>=1 &&a<=n&&b>=1 &&b<=m&&h[x][y]>h[a][b]) { f[x][y]=max (f[x][y],dp (a,b)+1 ); } } return f[x][y]; } int main () cin>>n>>m; for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=m;j++) { cin>>h[i][j]; } } memset (f,-1 ,sizeof (f)); int res=0 ; for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=m;j++) { res=max (res,dp (i,j)); } } cout<<res; return 0 ; }
贪心 区间问题 区间贪心讨论按左端点、右端点排序,然后依次枚举每个区间
区间选点 将每个区间按照右端点从小到大进行排序
从前往后枚举区间,end值初始化为无穷小
如果本次区间不能覆盖掉上次区间的右端点, ed < range[i].l
说明需要选择一个新的点, res ++ ; ed = range[i].r;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <iostream> #include <algorithm> using namespace std;const int N=100010 ;int n;struct Range { int l,r; bool operator <(const Range&W)const { return r<W.r; } }range[N]; int main () scanf ("%d" ,&n); for (int i=0 ;i<n;i++) scanf ("%d%d" ,&range[i].l,&range[i].r); sort (range,range+n); int res=0 ,ed=-2e9 ; for (int i=0 ;i<n;i++) { if (range[i].l>ed) { res++; ed=range[i].r; } } printf ("%d" ,res); return 0 ; }
最大不相交区间个数 和上一题代码是一样的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <iostream> #include <algorithm> using namespace std;const int N=100010 ;int n;struct Range { int l,r; bool operator <(const Range&W)const { return r<W.r; } }range[N]; int main () scanf ("%d" ,&n); for (int i=0 ;i<n;i++) scanf ("%d%d" ,&range[i].l,&range[i].r); sort (range,range+n); int res=0 ,ed=-2e9 ; for (int i=0 ;i<n;i++) { if (range[i].l>ed) { res++; ed=range[i].r; } } printf ("%d" ,res); return 0 ; }
区间分组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 #include <iostream> #include <algorithm> #include <queue> using namespace std;const int N=100010 ;int n;struct Range { int l,r; bool operator <(const Range&W)const { return l<W.l; } }ranges[N]; int main () scanf ("%d" ,&n); for (int i=0 ;i<n;i++) { scanf ("%d%d" ,&ranges[i].l,&ranges[i].r); } sort (ranges,ranges+n); priority_queue<int ,vector<int >,greater<int > >heap; for (int i=0 ;i<n;i++) { auto r=ranges[i]; if (heap.empty ()||heap.top ()>=r.l) heap.push (r.r); else { heap.pop (); heap.push (r.r); } } printf ("%d" ,heap.size ()); return 0 ; }
区间覆盖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> #include <algorithm> using namespace std;const int N=100010 ;struct Range { int l,r; bool operator <(const Range&W)const { return l<W.l; } }ranges[N]; int main () int st,ed; scanf ("%d%d" ,&st,&ed); int n; scanf ("%d" ,&n); for (int i=0 ;i<n;i++) { scanf ("%d%d" ,&ranges[i].l,&ranges[i].r); } sort (ranges,ranges+n); int res=0 ; bool suc=false ; for (int i=0 ;i<n;i++) { int j=i,r=-2e9 ; while (j<n&&ranges[j].l<=st) { r=max (r,ranges[j].r); j++; } if (r<st) { res=-1 ; break ; } res++; if (r>=ed) { suc=true ; break ; } st=r; i=j-1 ; } if (suc) { printf ("%d" ,res); }else printf ("-1" ); return 0 ; }
Huffman树 合并果子 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> #include <algorithm> #include <queue> using namespace std;int main () int n; scanf ("%d" ,&n); priority_queue<int ,vector<int >,greater<int > >heap; while (n--) { int x; scanf ("%d" ,&x); heap.push (x); } int res=0 ; while (heap.size ()>1 ) { int a=heap.top ();heap.pop (); int b=heap.top ();heap.pop (); res+=(a+b); heap.push (a+b); } printf ("%d\n" ,res); return 0 ; }
排序不等式 排队打水,护航问题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> #include <algorithm> using namespace std;typedef long long LL;const int N=100010 ;int n;int t[N];int main () scanf ("%d" ,&n); for (int i=0 ;i<n;i++) scanf ("%d" ,&t[i]); sort (t,t+n); reverse (t,t+n); LL res=0 ; for (int i=0 ;i<n;i++) res+=t[i]*i; printf ("%lld\n" ,res); return 0 ; }
绝对值不等式 货仓选址 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #include <iostream> #include <algorithm> using namespace std;const int N=100010 ;int n;int q[N];int main () scanf ("%d" ,&n); for (int i=0 ;i<n;i++) scanf ("%d" ,&q[i]); sort (q,q+n); int res=0 ; for (int i=0 ;i<n;i++) res+=abs (q[i]-q[n/2 ]); printf ("%d\n" ,res); return 0 ; }
推公式 耍杂技的牛 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <iostream> #include <algorithm> using namespace std;typedef pair<int ,int >PII;const int N=50010 ;int n;PII cow[N]; int main () scanf ("%d" ,&n); for (int i=0 ;i<n;i++) { int s,w; scanf ("%d%d" ,&w,&s); cow[i]={w+s,w}; } sort (cow,cow+n); int res=-2e9 ,sum=0 ; for (int i=0 ;i<n;i++) { int s=cow[i].first-cow[i].second,w=cow[i].second; res=max (res,sum-s); sum+=w; } printf ("%d" ,res); return 0 ; }
算法复习 attention:
回溯法
递归&&子集树框架 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void backtrack (int t) if (t>n) output (); else { compute () if (constraint (t)) { changestate (); backtrack (t+1 ); stateback (); } if (bound (t)) { backtrack (t+1 ); } compute_back () } }
迭代框架 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void backtrack (void ) int t=1 ; while (t>0 ) { if (f (n,t)<g (n,t)) { for (int i=f (n,t);i<=g (n,t);i++) { if (constraint (t)&&bound (t)) { if (solution (t)) output (); else t++; } } } else t--; } }
排列树框架 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void backtrack (int t) if (t>n) output (); else for (int i=t;i<=n;i++) { if (constraint (t)&&bound (t)) { swap (x[i],x[t]); changestate (); backtrack (t+1 ); changestate (); swap (x[i],x[t]); } } }
装载问题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <iostream> using namespace std;int n;int cw=0 ,cbest=0 ;int r;int c1,c2;int x[100 ];int bestx[100 ];int w[100 ];void backtrack (int t) if (t>n) { if (cw>cbest) { for (int i=1 ;i<=n;i++) bestx[i]=x[i]; cbest=cw; } return ; } r-=w[t]; if (cw+w[t]<=c1) { x[t]=1 ; cw+=w[t]; backtrack (t+1 ); x[t]=0 ; cw-=w[t]; } if (cw+r>cbest) { x[t]=0 ; backtrack (t+1 ); } r+=w[t]; } int main () cin>>n>>c1; for (int i=1 ;i<=n;i++) { cin>>w[i]; r+=w[i]; } backtrack (1 ); for (int i=1 ;i<=n;i++) cout<<bestx[i]<<" " ; return 0 ; }
input
python
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 n = 0 c = 0 w = [0 ]*100 x = [0 ]*100 bestx = [0 ]*100 cbest = 0 cw = 0 r = 0 def backtrack (t ): global cw,cbest,x,bestx,r if t>n: if cw>cbest: bestx = x.copy() cbest = cw return r -= w[t] if cw+w[t]<= c: x[t] = 1 cw+=w[t] backtrack(t+1 ) x[t] = 0 cw-=w[t] if cw+r>cbest: x[t] = 0 backtrack(t+1 ) r += w[t] def main (): global n,c,w,r n,c = map (int ,input ().split()) w[1 :n+1 ] = list (map (int ,input ().split())) r = sum (w[1 :n+1 ]) backtrack(1 ) print (cbest) print (bestx[1 :n+1 ]) main()
批处理作业调度 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 #include <iostream> using namespace std;const int N=1010 ;int M[N][N];int x[N];int bestx[N];int f1,f2[N];int bestf=1000000 ,n,f;void backtrack (int t) if (t>n) { if (f<bestf) { for (int i=1 ;i<=n;i++) { bestx[i]=x[i]; } bestf=f; } return ; } for (int i=t;i<=n;i++) { f1+=M[x[i]][1 ]; f2[t]=((f2[t-1 ]>f1)?f2[t-1 ]:f1)+M[x[i]][2 ]; f+=f2[t]; if (f<bestf) { swap (x[i],x[t]); backtrack (t+1 ); swap (x[i],x[t]); } f1-=M[x[i]][1 ]; f-=f2[t]; } } int main () cin>>n; for (int i=1 ;i<=n;i++) { cin>>M[i][1 ]>>M[i][2 ]; } for (int i=1 ;i<=n;i++) x[i]=i; backtrack (1 ); for (int i=1 ;i<=n;i++) cout<<bestx[i]>>" " ; cout<<endl; cout<<bestf; return 0 ; }
input:
八皇后问题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <iostream> #include <cmath> using namespace std;const int N=1010 ;int x[N];int sum,n;bool place (int t) for (int j=1 ;j<t;j++) { if (abs (j-t)==abs (x[j]-x[t])) return false ; } return true ; } void backtrack (int t) if (t>n) { sum++; return ; } for (int i=t;i<=n;i++) { swap (x[i],x[t]); if (place (t)) backtrack (t+1 ); swap (x[i],x[t]); } } int main () cin>>n; for (int i=1 ;i<=n;i++) { x[i]=i; } backtrack (1 ); cout<<sum; return 0 ; }
input
0-1背包问题简化版本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <iostream> using namespace std;const int N=1010 ;int x[N],bestx[N];int bestv,cv;int cw,r;int w[N],v[N];int c,n;void backtrack (int t) if (t>n) { if (cv>bestv) { for (int i=1 ;i<=n;i++) { bestx[i]=x[i]; } bestv=cv; } return ; } r-=v[t]; if (cw+w[t]<=c) { x[t]=1 ; cv+=v[t]; cw+=w[t]; backtrack (t+1 ); x[t]=0 ; cv-=v[t]; cw-=w[t]; } if (cv+r>bestv) { x[t]=0 ; backtrack (t+1 ); } r+=v[t]; } int main () cin>>n>>c; for (int i=1 ;i<=n;i++) { cin>>w[i]; } for (int i=1 ;i<=n;i++) { cin>>v[i]; r+=v[i]; } backtrack (1 ); for (int i=1 ;i<=n;i++) { cout<<bestx[i]<<" " ; } cout<<endl<<bestv; return 0 ; }
最大团问题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 #include <iostream> using namespace std;const int N=1010 ;int G[N][N];int x[N],bestx[N];int r,cbest,cv;int n,m;bool choose (int t) for (int i=1 ;i<t;i++) { if (x[i]==1 &&G[i][t]==0 ) return false ; } return true ; } void backtrack (int t) if (t>n) { if (cv>cbest) { for (int i=1 ;i<=n;i++) { bestx[i]=x[i]; } cbest=cv; } return ; } r--; if (choose (t)) { cv++; x[t]=1 ; backtrack (t+1 ); cv--; x[t]=0 ; } if (cv+r>cbest) { x[t]=0 ; backtrack (t+1 ); } r++; } int main () cin>>n>>m; r=n; int u,v; for (int i=1 ;i<=m;i++) { cin>>u>>v; G[u][v]=1 ; G[v][u]=1 ; } backtrack (1 ); for (int i=1 ;i<=n;i++) { cout<<bestx[i]<<" " ; } cout<<endl<<cbest; return 0 ; }
input
1 2 3 4 5 6 7 8 5 7 1 2 1 4 1 5 2 5 2 3 3 5 4 5
TSP问题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 #include <iostream> using namespace std;const int N=1010 ;int G[N][N];int x[N],bestx[N];int cbest=1000000 ,cw;int n;void backtrack (int t) if (t==n) { if (G[x[n]][x[n-1 ]]>0 &&G[x[n]][1 ]>0 &&(cw+G[x[n]][x[n-1 ]]+G[x[n]][1 ]<cbest)) { for (int j=1 ;j<=n;j++) { bestx[j]=x[j]; } cbest=cw+G[x[n]][x[n-1 ]]+G[x[n]][1 ]; } return ; } for (int i=t;i<=n;i++) { if (G[x[t-1 ]][x[i]]>0 &&(cw+G[x[t-1 ]][x[i]]<cbest)) { swap (x[i],x[t]); cw+=G[x[t-1 ]][x[t]]; backtrack (t+1 ); cw-=G[x[t-1 ]][x[t]]; swap (x[i],x[t]); } } } int main () cin>>n; for (int i=1 ;i<=n;i++) { for (int j=1 ;j<=n;j++) { cin>>G[i][j]; } x[i]=i; } backtrack (2 ); for (int i=1 ;i<=n;i++) { cout<<bestx[i]<<" " ; } cout<<"1" <<endl<<cbest; return 0 ; }
input
1 2 3 4 5 4 -1 30 6 4 30 -1 5 10 6 5 -1 20 4 10 20 -1
随机化算法 数值随机化算法
投点法计算π:设有一半径为r的圆及其外切四边形,向该正方形随机地投掷n个点,设落入圆内的点数为k,由于所投入的点再正方形上均匀分布,故落入圆中的点的概率为。。,当n足够大时,k与n的比就逼近这一概率,故π=。。。
计算定积分:向单位正方形内随机地投n个点,如果有m个点落入G内,由于所投点均匀地分布在正方形上,故当n足够,可近似计算G为
解线性方程组,